
之前分析各种组件或者框架的反序列化漏洞,fastjson或者shiro或者weblogic还有spring;其漏洞出发点都是在readObject;但是具体为什么是要在readObject点触发还没有细致的学习,今天恶补一下Java的原生序列化和反序列化;
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
简单写一个demo来对序列化和反序列化进行一个debug学习;模仿一波类似反序列化漏洞点;
1 | import java.io.*; |
由这个程序来简单debug一下;
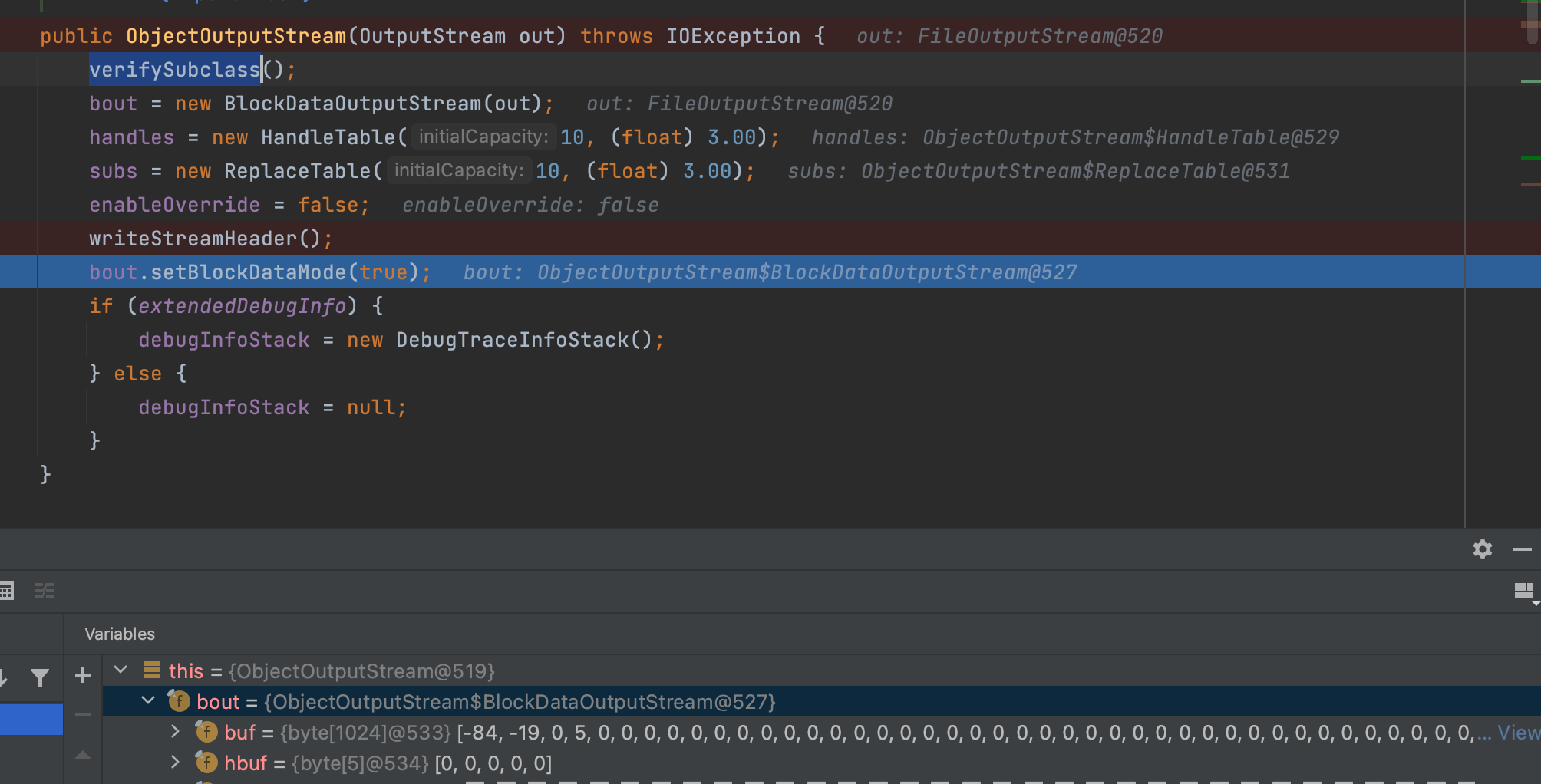
verifySubclass函数确定继承权限;这里ObjectOutputStream自然符合;
new一个BlockDataOutputStream底层流对象往out也就是FileOutputStream里写数据;FileOutputStream里调用open(name, append);写入文件中;追溯name和append;不难发现;
1 | String name = (file != null ? file.getPath() : null);//append==false; |
回归上图,构造两个Table;接着writeStreamHeader方法写入序列化头(魔术头,版本号);接着bout打开缓冲区;写入的魔术头,版本号写入到FileOutputStream流中,然后再写入文件中,这里可debug去看下目标文件;

可以看到释放缓冲区之后会将内容写入到文件中;整个过程是动态的、实时的,并非是最后一下子写入文件;因为涉及到很多缓冲区对外的开和关;下面会分析;
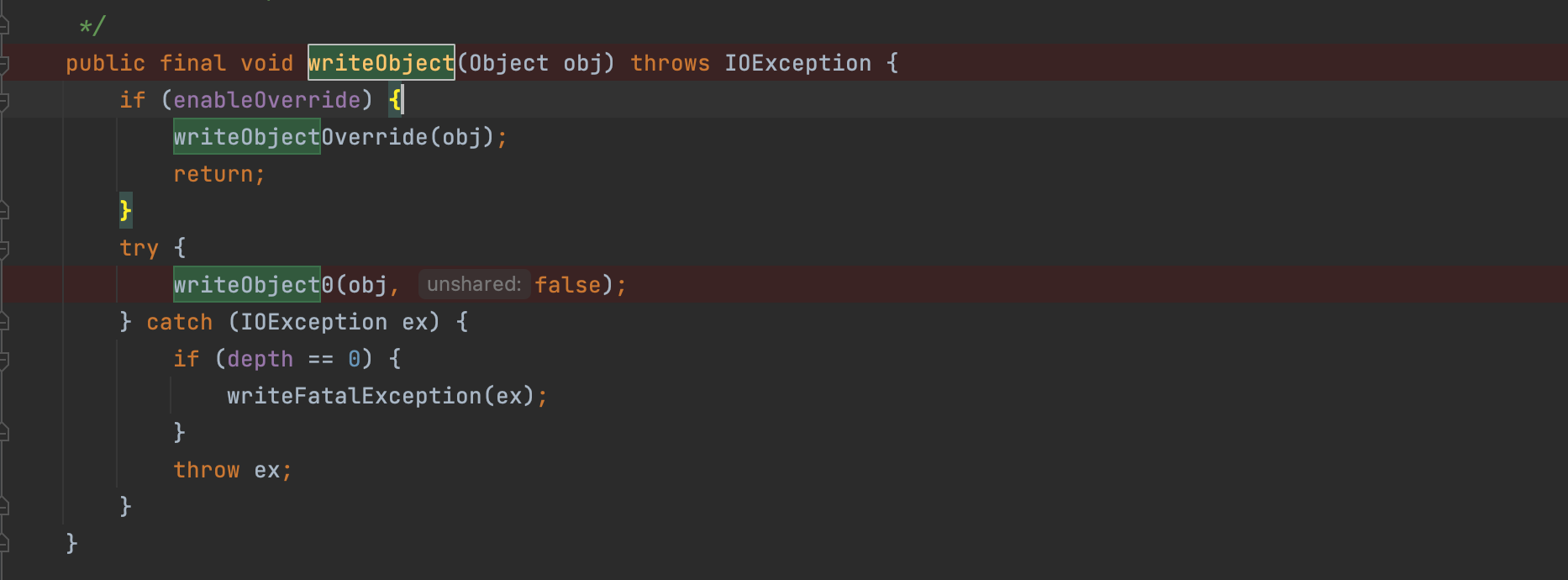
enableOverride属性在初始化的时候被设置为false;这里直接去拿writeObject0;在writeObject0中先关闭缓冲区对外通道;然后利用lookup方法返回desc;方便之后对类进行内省;

最后判断其继承的类型;从而进行相应的write函数调用;因为继承Serializable,所以这里是以二进制的形式write出来;这也解释了为什么序列化要继承Serializable接口;


向缓冲区buf里写入TC_OBJECT;然后调用writeClassDesc写入类的元数据;
在序列化数据之前,会先对对象进行类型的判别;
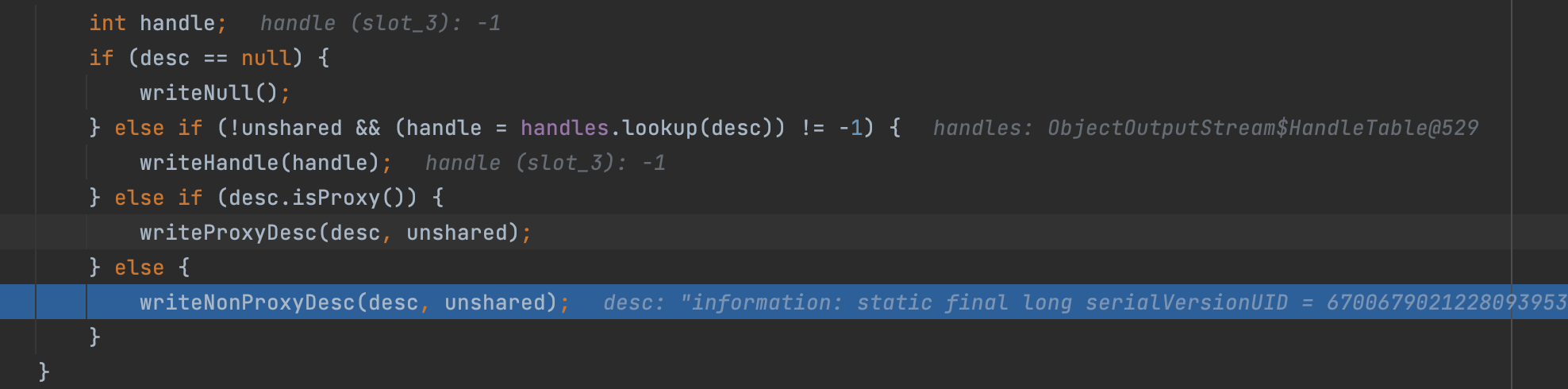
一种是Null,一种是handle一种是Proxy代理类型,最后一种是一般类型;这里自己随便写的一个类自然是一般类型,所以进入writeNonProxyDesc方法中;

先将TC_CLASSDESC标识写入buf缓冲区,为了避免重复覆盖,利用了pos探针去进行标识,所以此TC_CLASSDESC标识写在byte缓冲区的第二个元素位置;这点追溯下不难发现;
向下进入writeClassDescriptor方法;写入指定的类描述符的对象输出流;这里通俗点来讲就是向ObjectOutputStream流中的缓冲区写入目标类属性的数量,目标类的属性类型和属性名;其实本质上来说是调用了writeNonProxy方法;

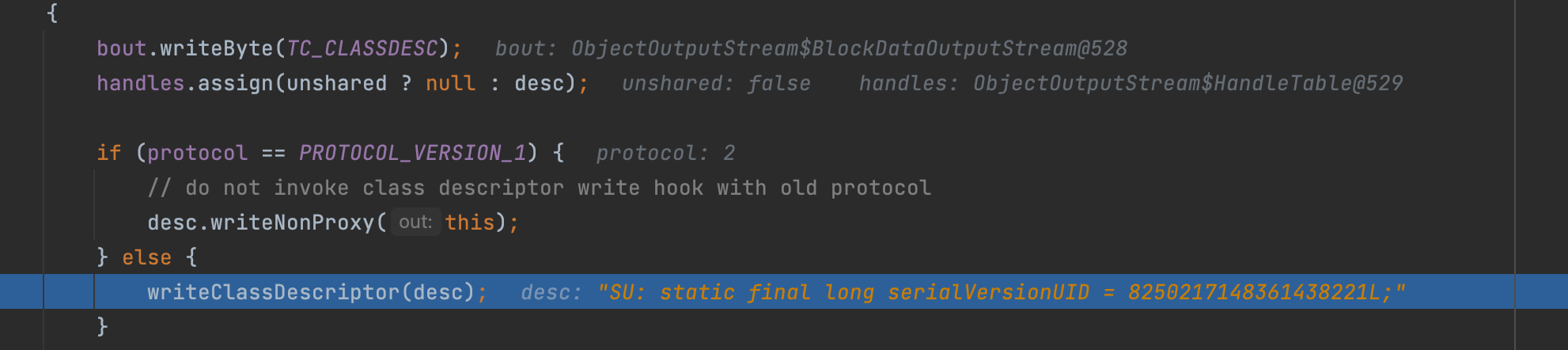
writeNonProxy里也有写入一些重要的点,这里追溯一下:可以看到写入序列化目标类名和serialVersionUID;

然后判断写入标识;因为目标类继承了可序列化接口,所以目标类可序列化,那么自然写入序列化标识 SC_SERIALIZABLE;
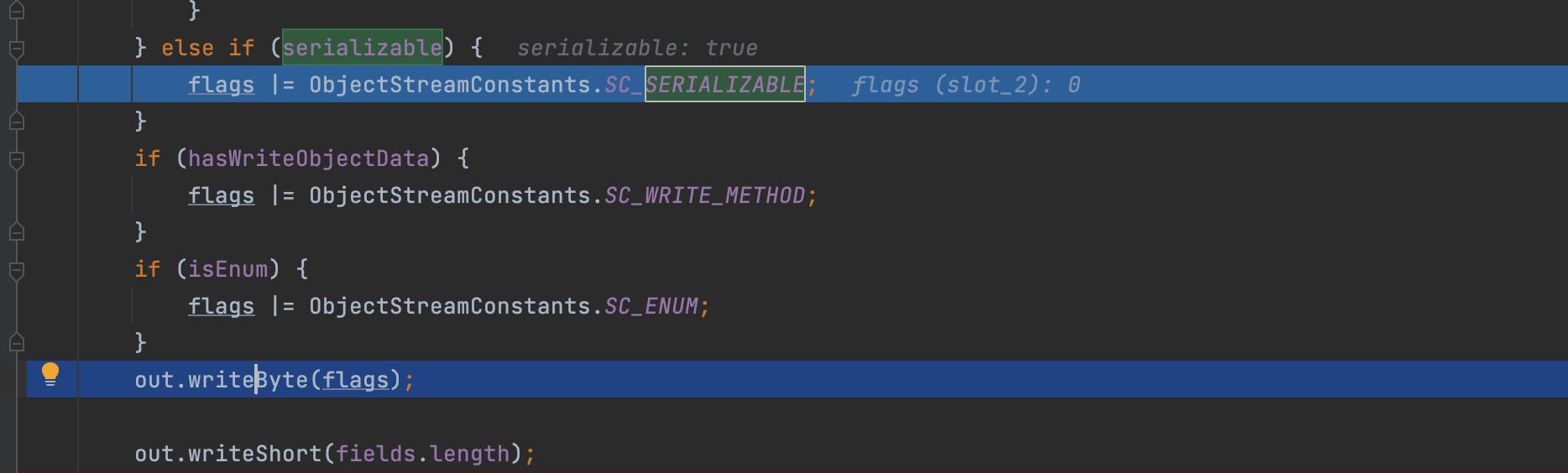
写完之后利用setBlockDataMode函数打开缓冲区对外通道释放掉缓冲区,将缓冲区的内容传入文件输出流中,最后写入文件;


然后再次关闭关闭缓冲区对外的通道,写入TC_ENDBLOCKDATA (对象的可选块数据块的结尾)。至此属性类型和属性名还有serialVersionUID等写入完毕;

然后递归调用writeClassDesc写入父类元信息。看到Super就无疑了;

和之前的流程一样,先写入TC_CLASSDESC;然后写入父类的属性类型和属性名、serialVersionUID等等;这点和上面的一样,不再赘述;
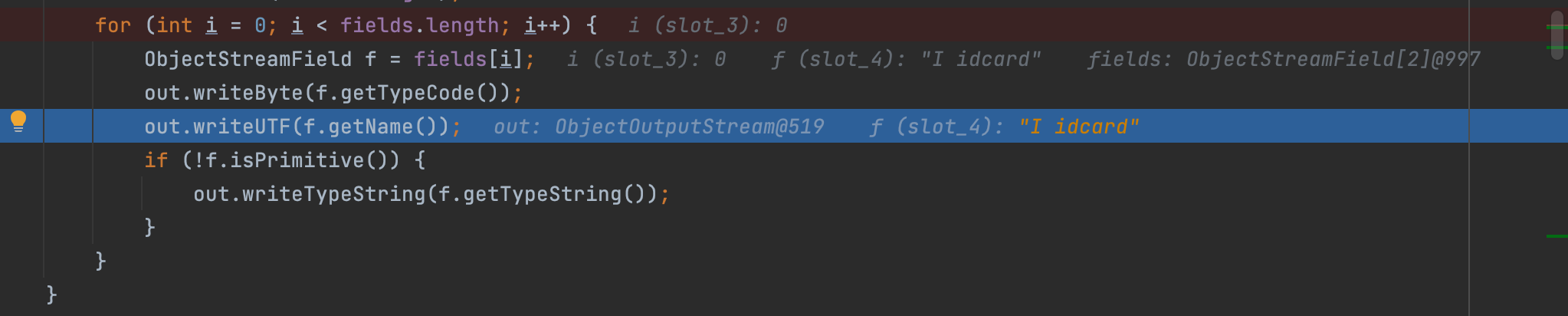
代码不是很难理解;写完父类属性信息之后再次打开缓冲区对外通道,写入文件流然后实时写入文件;

最后当然再向缓冲区写入TC_ENDBLOCKDATA以表示此过程写入结束;
上面这些流程走完之后就开始序列化写入数据了;

进入writeSerialData函数;利用getClassDataLayout方法拿到实例化目标类和其父类;然后进入for依次对两个类进行处理;
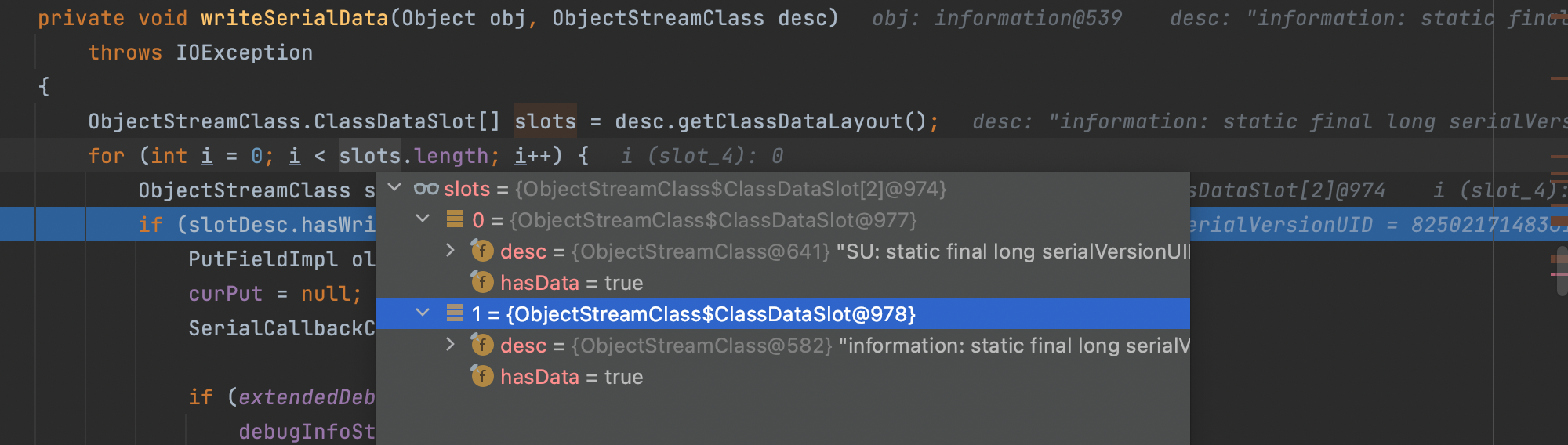
先检查目标类有没有自定义writeObject方法;也就是有没有重写writeObject方法;如果有则调用invokeWriteObject方法去执行自定义的writeObject方法;这自然是没有;

所以最后进入调用默认的序列化属性器;

进入defaultWriteFields函数;
首先拿到Class对象,然后判断Class对象和Obj实例化对象是否为空,并且进入isInstance函数;判断是否实例化;看下isInstance函数的说明;
Specifically, if this Class object represents a declared class, this method returns true if the specified Object argument is an instance of the represented class (or of any of its subclasses); it returns false otherwise.; 翻译过来大概如下:
具体地说,如果这个类对象表示一个声明的类,那么如果指定的对象参数是所表示的类(或其任何子类)的实例,那么这个方法返回true;否则返回false。
再具体一点针对于isInstance函数可以看这个链接https://blog.csdn.net/cumt951045/article/details/107798107;
这里是先来处理父类SU,obj(information)是SU的子类;所以自然符合;返回true;再进行逻辑运算最后为false;不抛出错误,继续向下进行;
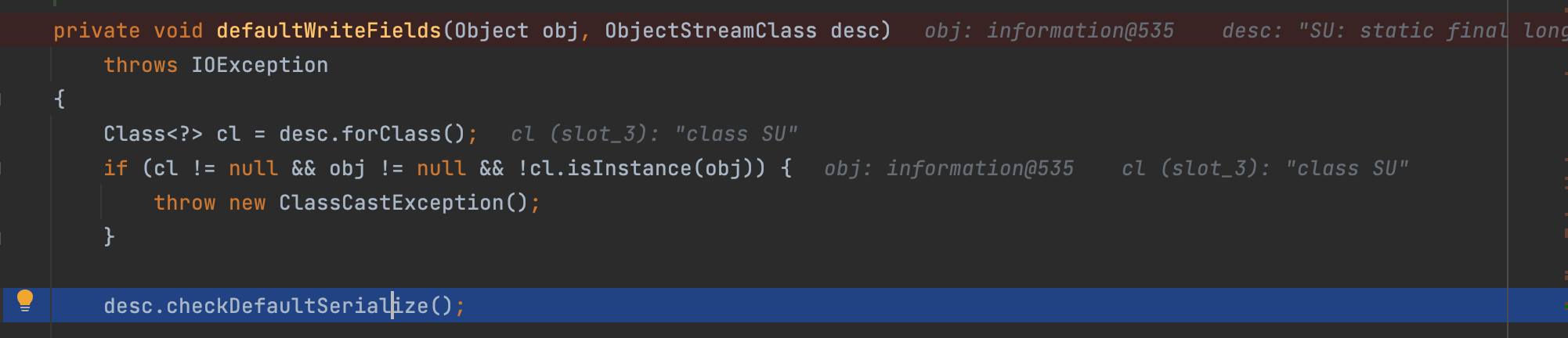
调用checkDefaultSerialize方法;检查对象有没有正确的初始化;然后排查默认序列化时异常;

然后去利用getPrimDataSize函数去获取基本类型的域的个数;然后生成存储基本类型域值的字节数组;获取基本类型域的值,然后将其类型和域名写入缓冲区中;这里是int所以写入为 I;(想请理解看参考后面down的结果)
然后获取对象的所有域;接着创建一个java数组对象类型的引用类型域数组;

至于基本类型域的概念具体可看此链接;
https://blog.csdn.net/weixin_34703307/article/details/114072459
通过getObjFieldValues函数拿到非原生数据的值,这里debug拿到的是ncu,也就是String school域;然后通过for循环,调用writeObject0函数下writeString方法写入序列化流中;
1 | long utflen = bout.getUTFLength(str); |
写入方法如上代码;写入相应标识和长度还有值;
最后附上down的结果;
1 | STREAM_MAGIC - 0xac ed |
更好的理解我采用如下的源码来表示;
1 | import java.io.*; |
反序列化很类似于序列化的操作;主要操作都是在function0里;
首先来说也是预处理;
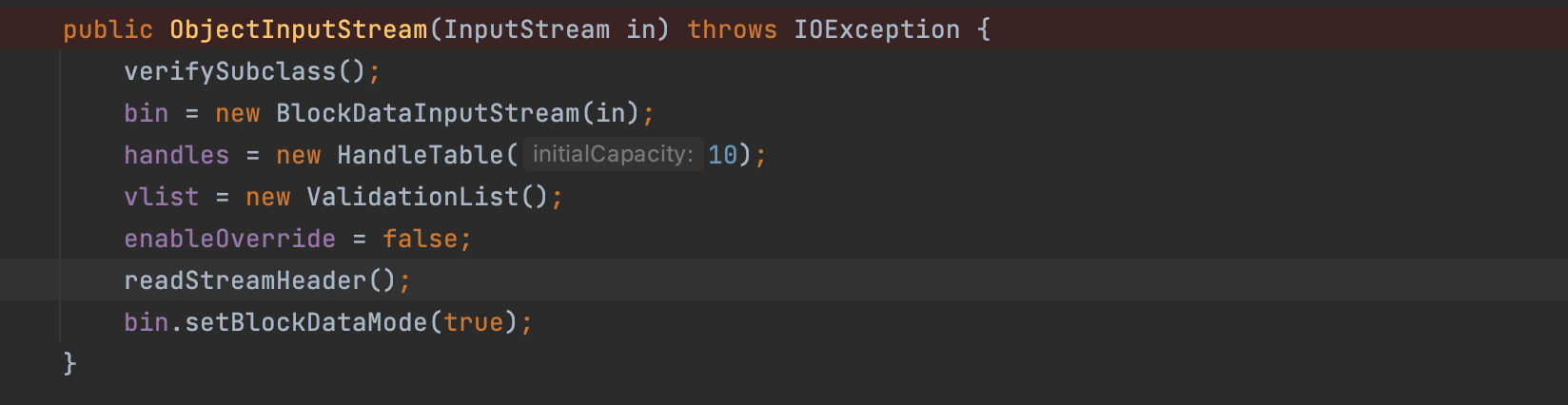
先来判别继承权限(简单点片面说就是判别此类是不是ObjectInputSream,文章末尾会分析verifySubclass函数),然后new一个底层的输入流;值得注意的是readStreamHeader方法会去读取STREAM_MAGIC和STREAM_VERSION头,进行判别是否相等以检测流是否损坏;当然,如果两端使用的JDK中这个类版本号不一致就会出现异常;抛出错误invalid stream header;然后打开缓冲区和内部的通道,释放缓冲区;数据被读取到ObjectInputStream内部;
然后开始调用readObject方法处理序列化的数据
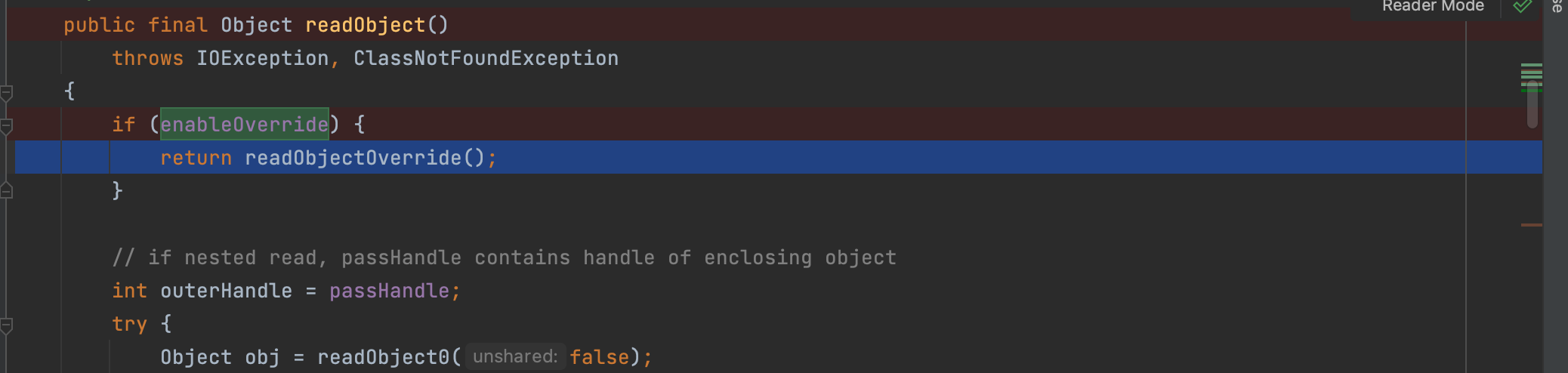
因为调用的是带有参数的ObjectInputStream方法,所以是需要有外界传入流;所以这里调用readObject0来进行处理;readObject0是ObjectInputStream的核心方法;

先判断一下整体的流当前是否处于块数据模式;然后拿到前数据块中剩余的未使用字节数;程序不允许有多余的未使用字节;所以如果有会抛出错误;然后关闭对内的通道;
接着读取标识;通过switch选择对应标识后数据的读取方式进行读取相应的数据;


case到object进行反序列化,整个object的反序化在readOrdinaryObject中;
这里程序写的很谨慎;先进行判断是不是Object的标识,如果不是抛出错误;反之继续向下进行;

在下面调用readClassDesc方法进行元数据的读取;和序列化写入是刚好反过来;这里是和序列化相同,也会判断目标class是否属于四种类型;经过case;

case到TC_CLASSDESC;处理并返回类描述符对象;说人话就是返回的是一个描述类的一个对象,主要包括类的名称,suid等各种域;也就是元数据;其实追溯一下不难发现,还是调用了readNonProxy方法;(readClassDescriptor方法下调用)
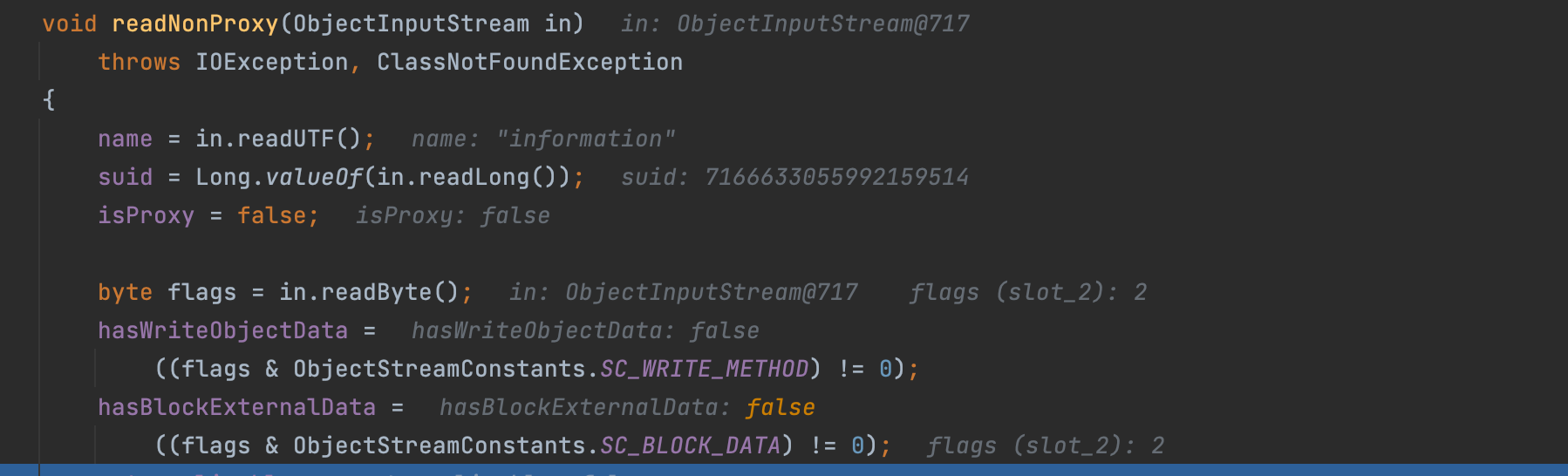
在此方法下,拿到类名,序列化id和序列化中标识类版本(0x02);然后接着拿到了class的属性数量,并且用for循环对输入流向后读取readByte;拿到了所有属性名;记录一下:

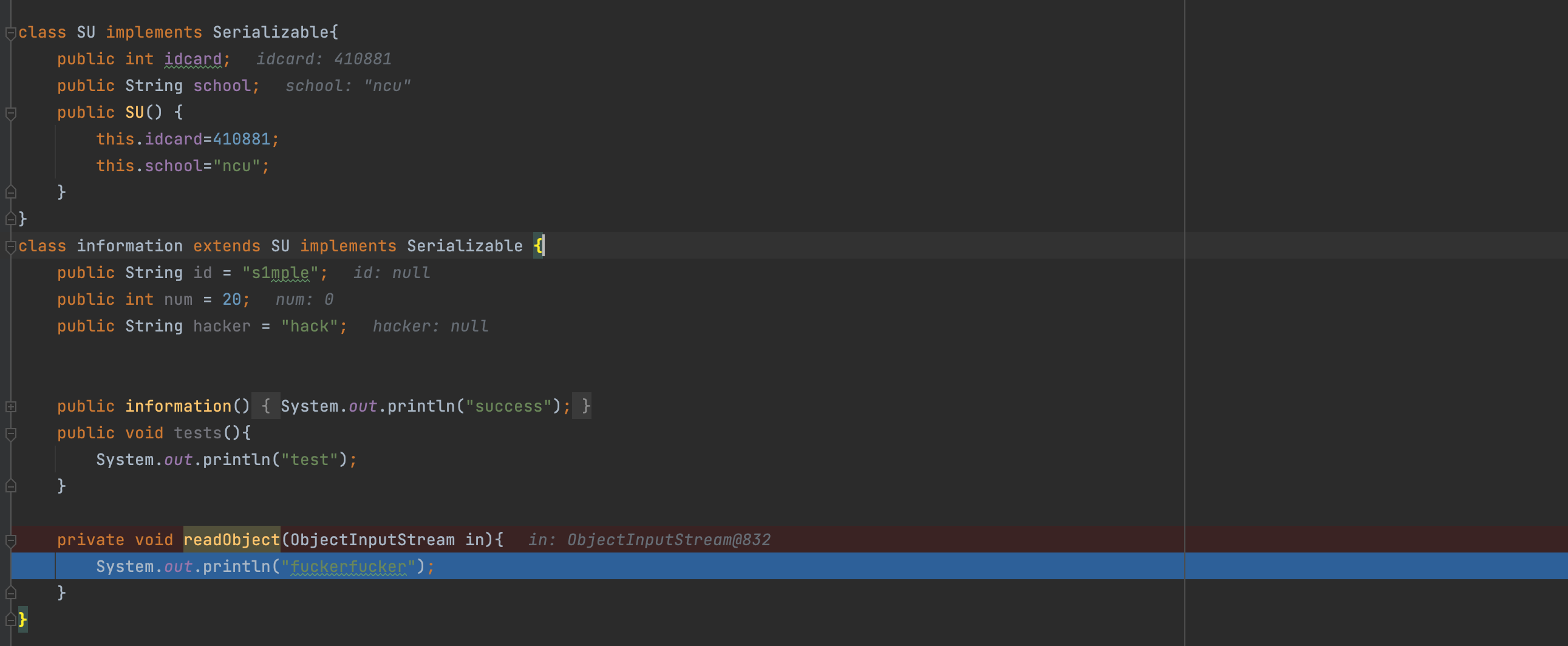
这里显然是拿到域的数量;information这个obj里有三个,这在序列化数据中有记录;读出域名和类型之后将其打包为ObjectStreamField;

这里在读取的时候会将读取的字符进行判断,代码很明显,这是因为在序列化写入的时候就是在非原生数据类型前加入相关字符;
然后将属性名和其类型一起打包;

然后在ObjectStreamField中case去修改ObjectStreamField对象下type的状态;
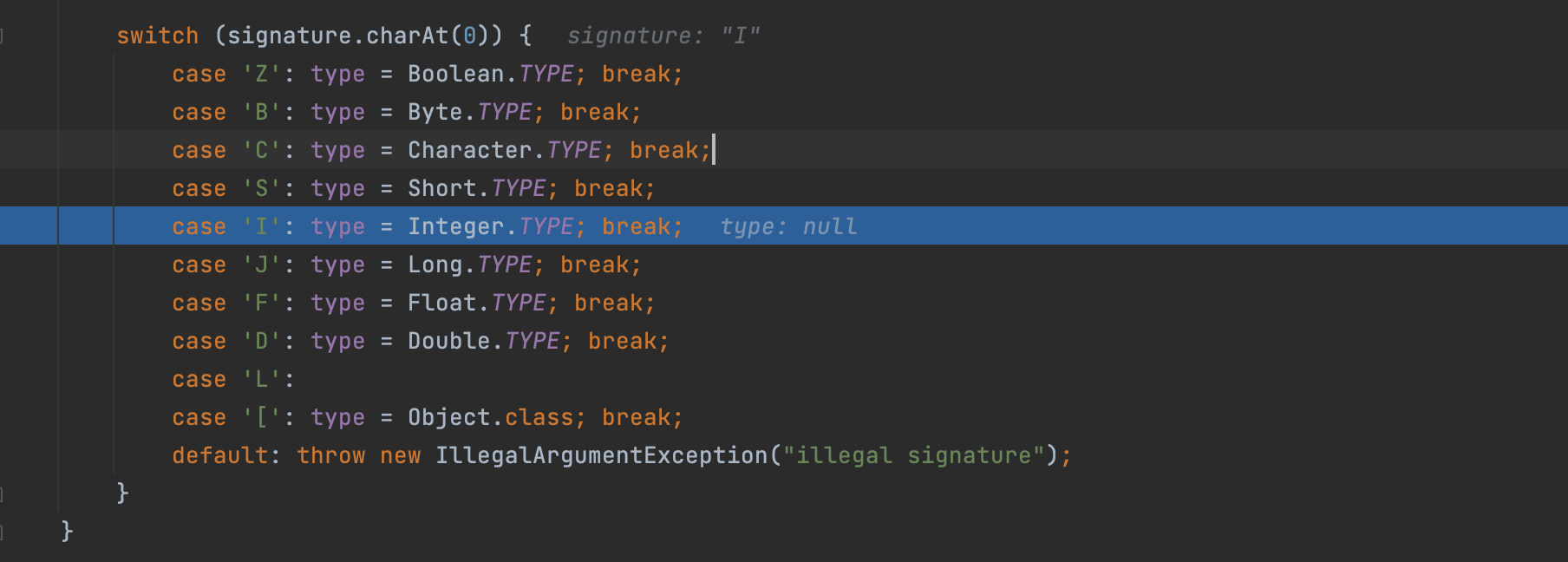
然后一路return;回到ObjectInputStream这个class下;

然后打开内部通道;清空缓冲区;
resolveClass对类类型进行构建;追溯一下看下处理流程;

这里不对class进行实例化;
继续向下:
initNonProxy又构建了类的元信息。并且检查是否有重写readObject,writeObejct,readObjectNoData,writeReplace,readResolve这些方法;如果重写则记录下来;
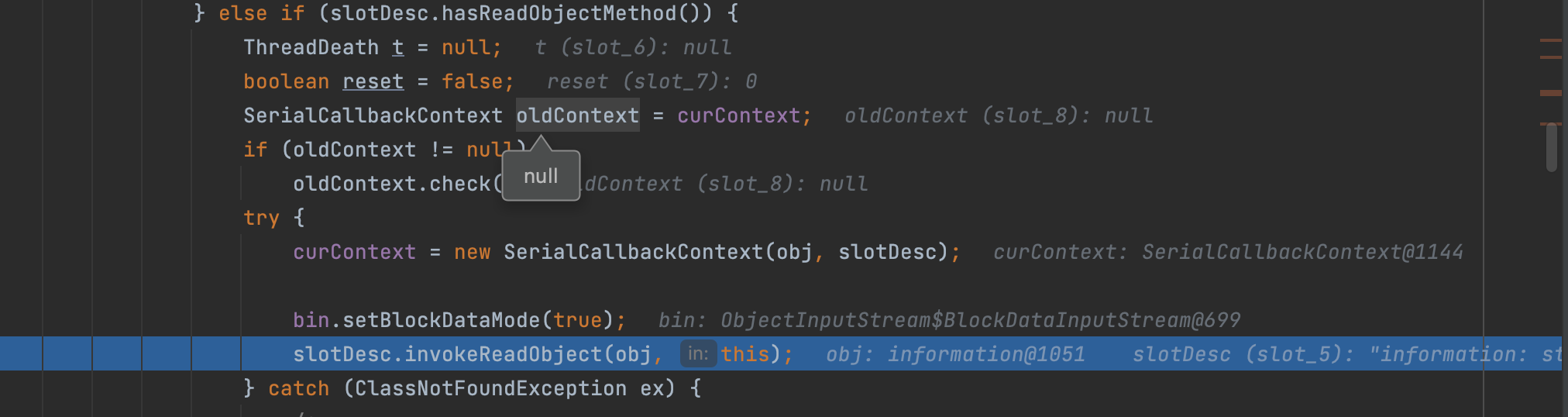
在此判断是否有重写的readObject方法,如果有则调用invokeReadObject方法去调用相应class下的readObject方法;这也就解释了为什么所有的readObject二进制反序列化链的起点都是相应class下的readObject的原因;当然这是在实例化完相关的父类obj之后进行的操作;反序列化的时候会先去进行父类里的处理,对其进行newInstance然后进行相关Field的赋值;父类完了之后才是处理子类;所以父类obj里的相关属性已经被赋了值;然后进行子类入口readObject的触发进行攻击; 一个图就可理解;
其实回去看一下主要的触发还是在如下:ObjectInputStream 下的readSerialData方法里;方法主要是对序列化的Field进行反序列化处理和反射赋值;
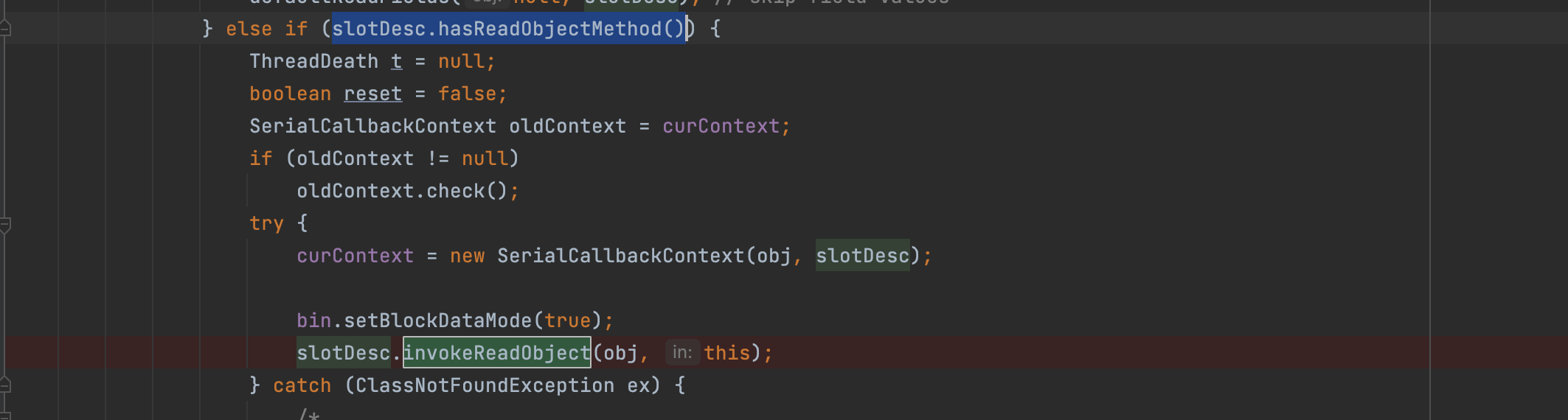
这里经过判断发现存在重写的readObject方法,所以直接进行调用;不会走原来的赋值操作(下图为原本正常逻辑赋值操作);
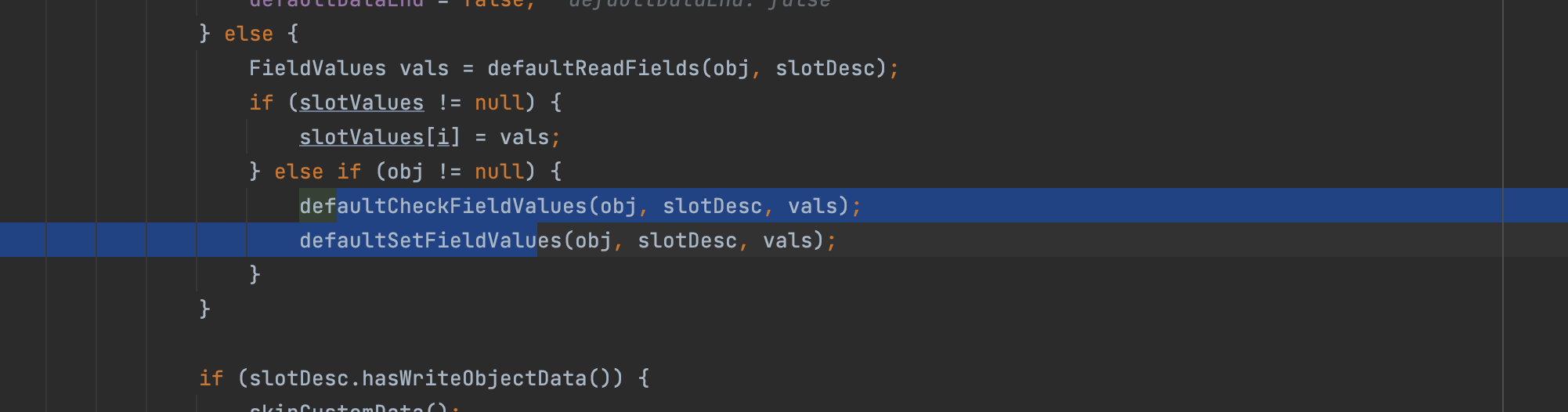
其实反序列化的漏洞也就是调用反射去给相应的class下的属性进行赋值;然后序列化成二进制文件之后,文件之中会保存相应的信息,然后触发readObject的时候就会碰到上述的也会去触发目标class下的readObject方法,然后经过其调用;我们规划好相应的链条属性的值;将其赋值为obj实例,就会链式反应最后进行到Runtime下或者Templateslmpl下,最后触发命令或者newInstance恶意class;或者触发jndi注入等等;当然还有更高级的攻击方法,比如攻击无文件落地攻击tomcat等等的操作,其实都是通过反序列化进行相关实现;