
因为之前分析过反序列化的一些点,之后有段时间没怎么看,现在重拾一下,理解一下漏洞原理和相关运行流程;
这篇文章主要分析一下Templatesmpl下的攻击方法,这种方法在实际攻击中有点鸡肋,但是凸显了很多fj的实现机制,可以更好理解fj解析流程;值得追踪一波;
这里拿着1.2.47的版本来进行分析一下走向;在进行序列化的时候会new一个SerializeWriter;然而在进行反序列化的时候则会去先初始化ParserConfig对象,以此获得基本的配置信息;具体的原理通过debug一下反序列化的过程不难发现;
这里先来放下之前的一般的exp攻击代码:
1 | import com.alibaba.fastjson.JSON; |
这里其实原理也不是很难,就是利用fastjson没有配置相应的反序列化器的时候会去自己构造一个新的javabean反序列化器;以此利用javabean的一些特性去执行某些敏感的函数对于一些敏感属性进行赋值;然后在一些敏感函数中又会调用到一些敏感的函数比如newInstance之类;从而达到攻击的效果;这里分析过apache commonscollections的师傅不难发现我这里使用的就是apache commonscollections的一个利用点,并非是原链条;只是和commonscollections的第二个链条的触发方式一样,都是利用自己设置的恶意类,然后去TemplatesImpl类下经过newInstance函数触发执行static模块的内容;本篇文章拿着这个利用点进行一些分析和追溯,再次深入理解fastjson的各个功能点;
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
这里我是开启了type的功能;其实是否开启对于缓存的攻击方式都无所谓;FastJson有一个全局缓存机制:在解析json数据前会先加载相关配置,调用addBaseClassMappings和loadClass函数将一些基础类和第三方库存放到mappings中;因为是写入缓存mapping中;当type功能没开启的时候,会从mappings或deserializers.findClass函数中获取反序列化的对应类,如果有,则直接返回绕过了黑名单。
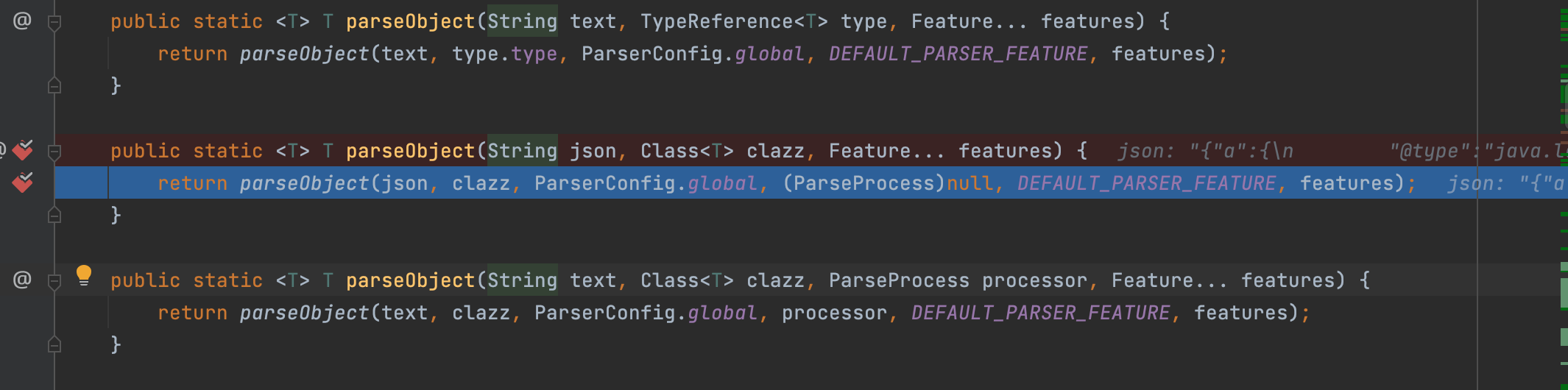
这边直接来追溯一下看到调用了parseObject的时候会去利用重载去拿到ParserConfig的实力化对象;这边追溯不难发现,ParserConfig中有个static模块;在调用的时候会优先执行;分析一下不难发现ParserConfig.global是ParserConfig的实例化对象;这就是在反序列化的时候会先去运载基础配置文件ParserConfig;ParserConfig文件中放入了很多默认写好的配置,比如内部注册的反序列化,还有内置的一些黑名单等等;至于原因自然是有一方面是为了提升相应的解析速度和一些相应的安全防范;
这边利用重载去到了209行下的parseObject方法;大致来看基本的步骤是三个;

这边可明显的看到带着基础配置类的实例化对象进入了后续的函数;

利用for循环,来配置反序列化启用的特征;这点也是我们最开始传入的feature;
第二大步:
拿到一个分析json词法的分析器parser;(对象)

这边来细致的走一波DefaultJSONParser这个class的实例化过程;
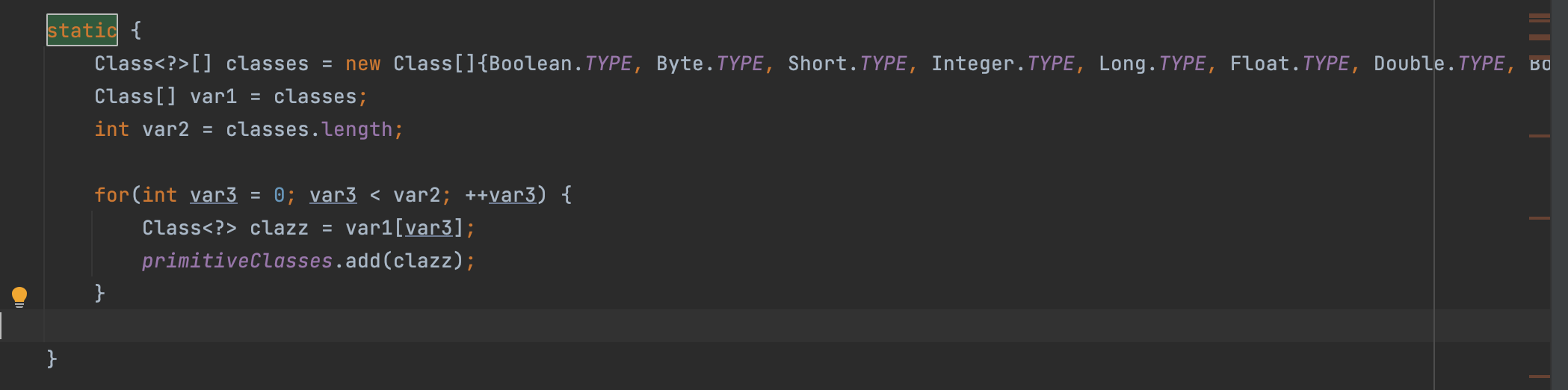
先来执行类的静态模块,这里加入了一些基本的对象;包括String、double、Short、Integer等;将其放入primitiveClasses中;用于以后的判断类型是否属于基础类型来使用;

1 | Class<?>[] classes = new Class[]{Boolean.TYPE, Byte.TYPE, Short.TYPE, Integer.TYPE, Long.TYPE, Float.TYPE, Double.TYPE, Boolean.class, Byte.class, Short.class, Integer.class, Long.class, Float.class, Double.class, BigInteger.class, BigDecimal.class, String.class}; |
执行完静态模块之后就开始去执行类的初始化方法,利用构造器的重载去new一个json的扫描器;JSONScanner类的生成同样先是执行类初始化

执行JSONScanner类的初始化的时候会去实例化其父类然后和其本身的初始化;相关代码如下所示;
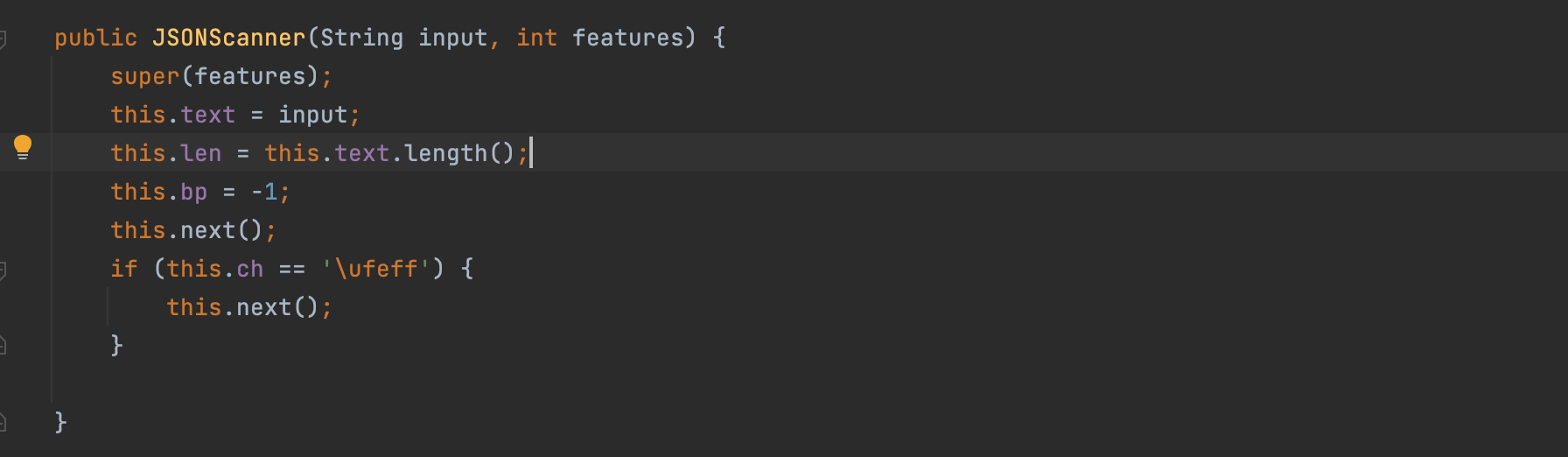
这里的if判断句是为了移除bom头;相关的原因和解释如下链接:
https://www.cnblogs.com/silentjesse/p/3919127.html
经过这一系列的操作之后,最后回到DefaultJSONParser方法;
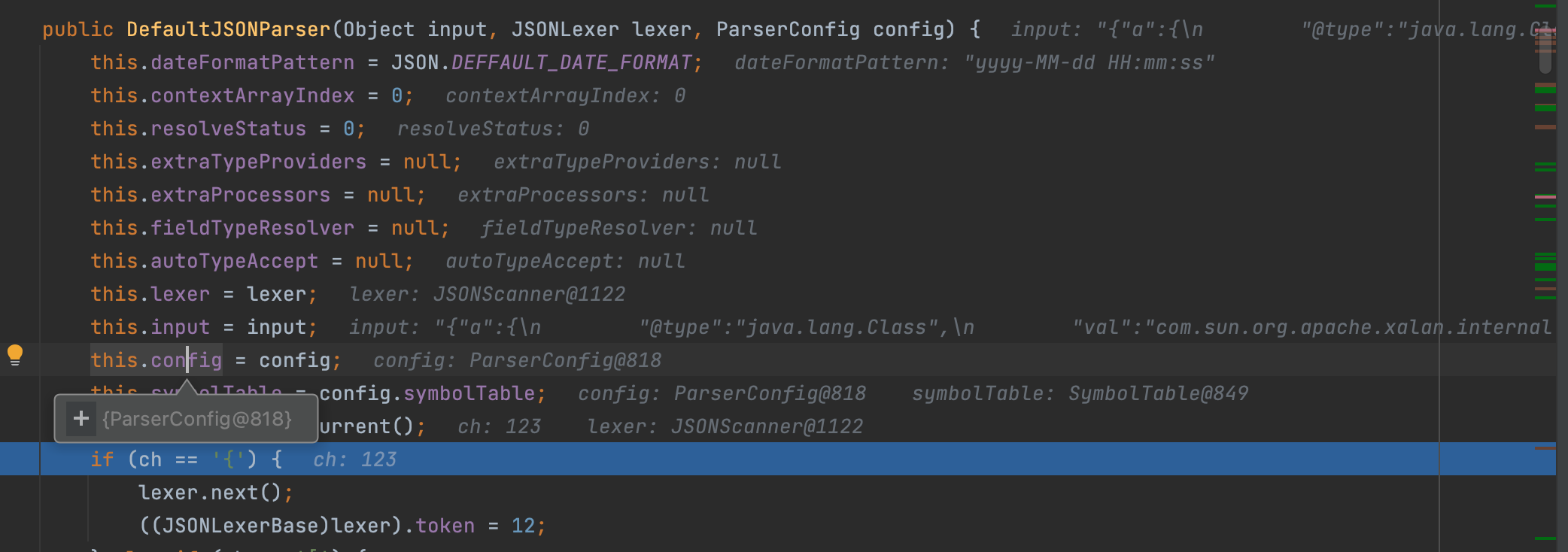
这里因为是{开头,所以token赋值为12;随着词法分析进行token进行会一直改变,token不一样意味着解析接下来json的策略也会变。token与字符的关联关系定义在com.alibaba.fastjson.parser.JSONToken;这里显然在读取{之后,将token设置为12,然后向后读取一位设置ch,读取到";
为了方便在报错的时候直接用token抛出相应字段的错误;
贴上源码:
1 | // |
不是很难理解,词法分析器主要是JSONScanner对象,只从名字上来看,这个对象就是json的扫描器,既然是扫描器,那么自然就是词法解析的主要对象;
三、开始对json数据进行解析:
前面这些基本的config设置和扫描器实例化完成之后就是调用json的词法解析器,对json的数据进行解析了;

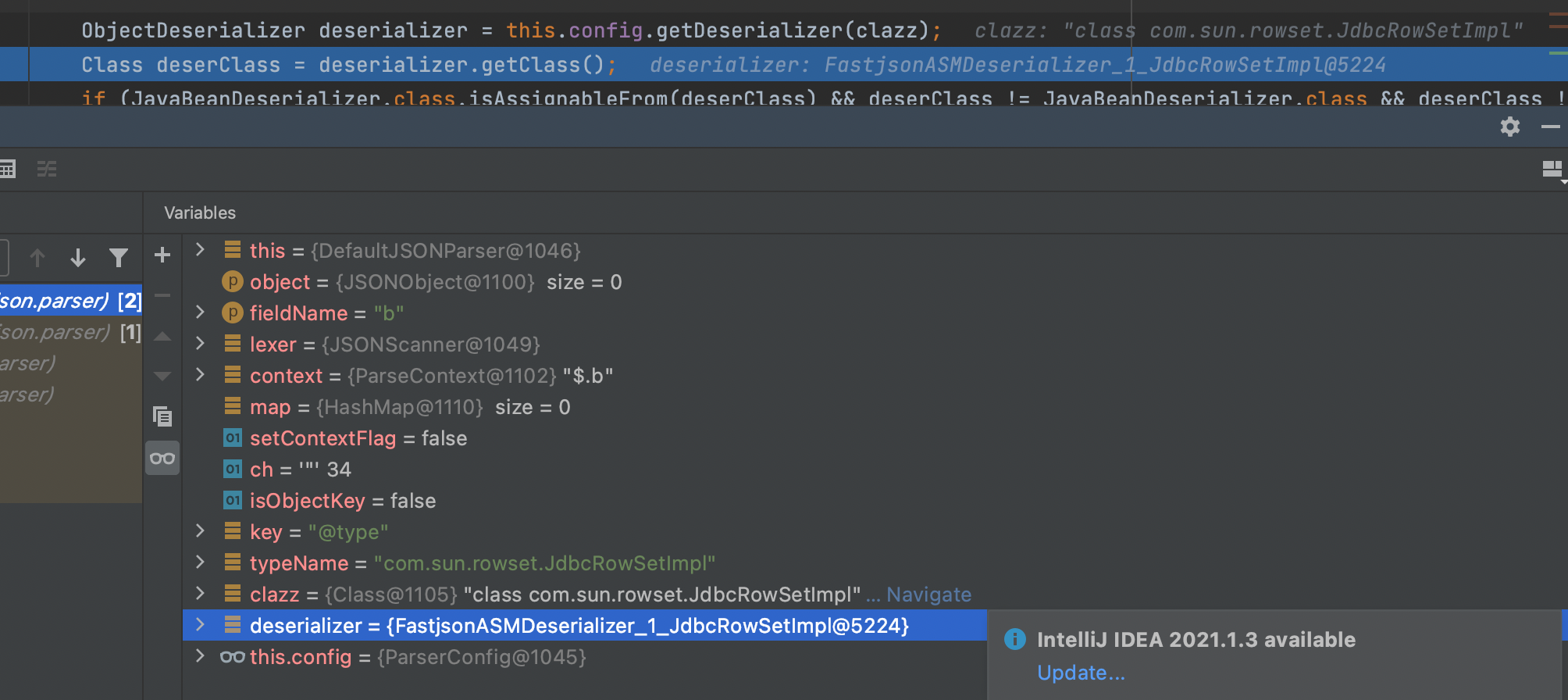
开始解析的时候会先到ParserConfig类下通过getDeserializer函数拿到相应的json解析器;这里也就是关联到我之前说的ParserConfig基础配置类,里面写有相应的内部注册的反序列化机制,规定某种类型用什么解析器去进行相应的解析,为的是加快解析的速度;用已经写好的解析器直接解析;根据传入的类类型的不同,config会返回不同的反序列化器。

这里的type就是在最开始我们传入的Object.class;
这边检查了一下type是否是泛型数组类型;


然后又回到DefaultJSONParser类下的parse函数
然后根据token进入到与其对应的分支之中;最开始因为是{开头,所以设置成了12;

进入praseObject方法进行解析;因为token是12,是字符{,所以过前面的if判断,进入后续解析操作,利用扫描器扫一下看看是不是有一些换行或者其他的特殊符;如果有的话直接调用扫描器的next函数进行跳过;读取下一位当作ch;

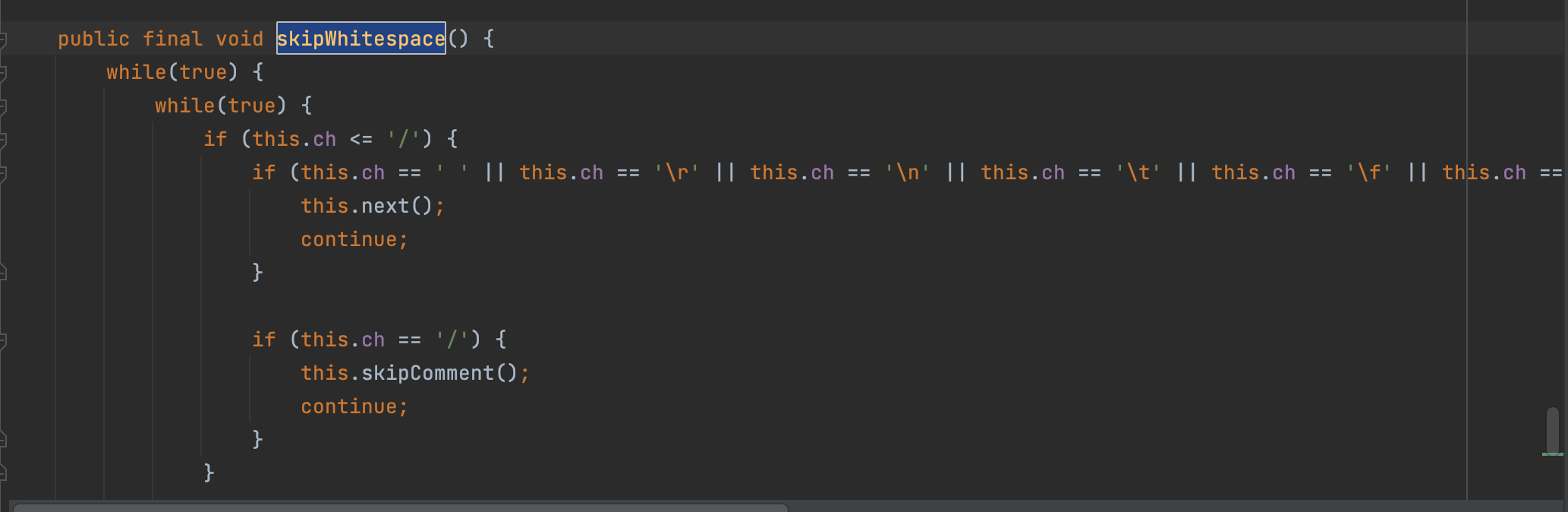
接着利用扫描器的getCurrent函数拿到当前的ch;如下图:
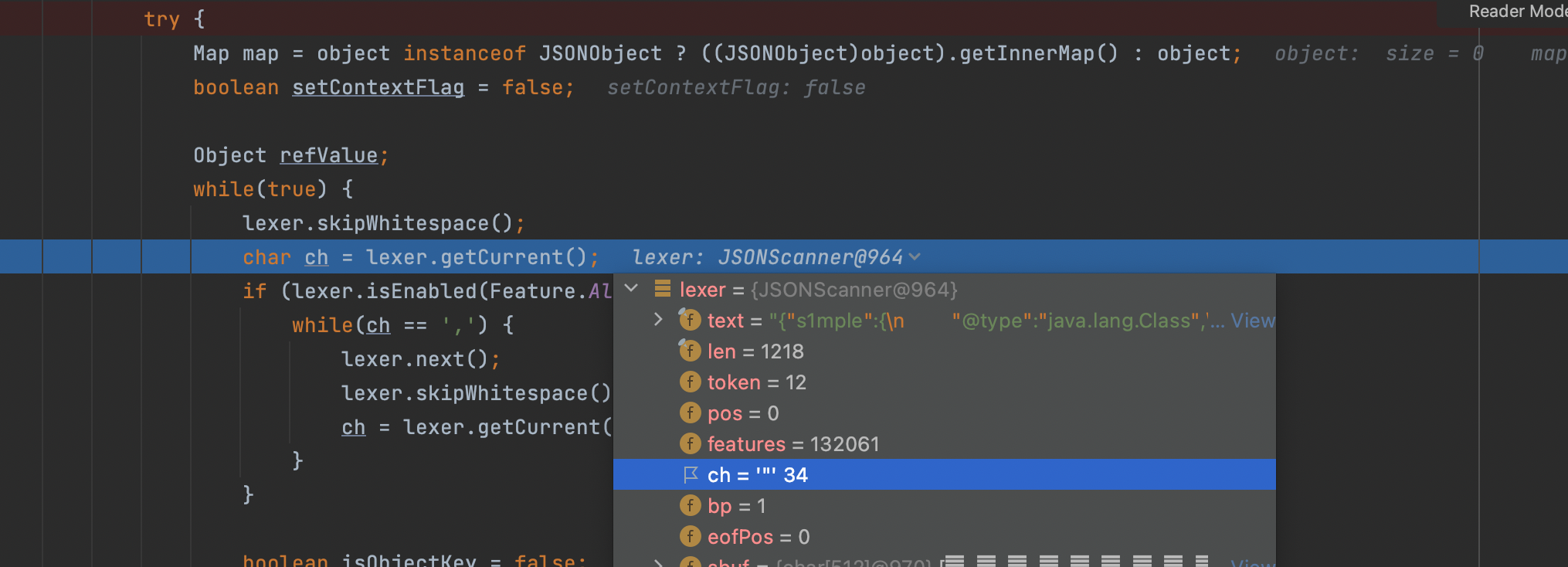
拿到ch之后向后判断扫描;

然后判断引号成立之后,利用scanSymbol函数拿到当前引号和下一个引号的中间内容;key;
拿到之后继续向后扫描;并且利用getCurrent函数拿到后续的扫描符号;经过debug可看到如果不是字符:就会抛出错误;意味着我们传入的json必须合规;

这里经过debug发现确实是如此;然后根据规则继续向下判断,下一个符号为{;

这里经过fastjson的判断发现没有构成一个完整的buckets模式解析;就会继续向后扫描;

在扫描的途中会去判断现在拿到的key是否为@type;这里显然不是;最后再次回调parseObject函数;

再次回调和上次的唯一一个区别是,这次是完整的解析拿到了@type字段;并且进入后续的check中;
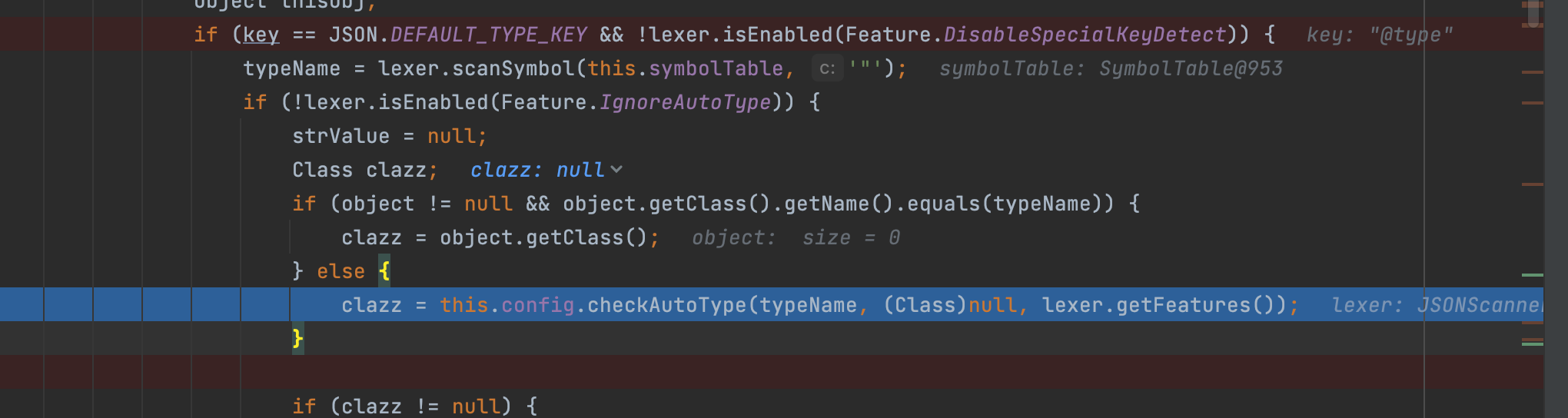
这里有必要提一下,因为没有开启autotype的功能,所以这里的check会先从最开始的fastjson的缓存中进行find类;也就是白名单,如果不存在的话就去进行匹配黑名单,如果匹配到黑名单则抛出error;反之退出;不会进行构造javabean反序列化器的操作;

这里将token设置为16;意味着json合法情况下,下一个符号是逗号;
根据java.lang.Class类对象,寻找针对java.lang.Class的反序列化器,之所以要找新的反序列化器是为了后续反序列化java.lang.Class的字段。这里自然在deserializers这个mapping中拿到了相应的反序列化解析器;

在MiscCodec这个反序列化解析器下,当判断为Class对象的时候会进行loadClass;


这里就是问题所在,在进行loadClass的时候将第三个参数cache赋值为true;造成的效果就是当在mapping中无法get到class的时候将class写入mapping;代码如下;这也就是1.2.47中危害的根本点,直接写入缓存,然后二次加载绕过黑名单;autotype 关 :基本攻击方法是在缓存中攻击或者在白名单中;白名单一般为空;然而开启autotype的时候可以在不触发黑名单的情况下去反序列化任意类;因为fj会去构造javaBean模式的反序列化器去对相应的类进行反序列化处理;

也是因为这个致命的缺点,可以让我们的恶意类逃过check;
过check之后,就会按照正常的解析流程去拿到反序列化器;找TemplatesImpl.class对应的反序列化器的任务还是委托给config,但是显然config并没有专门对付TemplatesImpl的反序列化器,所以走到了最后一个if条件,即把TemplatesImpl当作一个Java Bean来看并待根据TemplatesImpl实际情况定制一个JavaBeanDeserializer。


细看一下TemplatesImpl版的JavaBeanDeserializer定制过程。
一来先构建一个beaninfo

beaninfo构建的目的主要是拿到TemplatesImpl满足条件的getter、setter对应的Field和无参构造方法。获取这些办法就是常规的内省操作。

内省重点是满足条件的getter和setter
获取的首要点就是判断;非静态函数 && 返回类型为void或当前类 && 参数个数为1个;有注释或者以set开头;当然这里对于两个参数的方法有相应的处理,要求第一个参数是String类型,第二个参数为Object类型;不过主要还是拿到一个形参的函数;


然后根据相应的javabean规则去匹配相应的属性;

然后如果没有相应的属性值的话就去判断是不是boolean类型,如果是就会变更属性名再去属性列表里寻找,找不到则field参数返回null;propertyName参数还是之前的值;


这里先拿setter;然后属性都过完一遍之后再去内省getter;这里对getter的标准就比较的多;具体的要求我直接贴代码出来
1 | if (methodName.length() >= 4 && !Modifier.isStatic(method.getModifiers()) && builderClass == null && methodName.startsWith("get") && Character.isUpperCase(methodName.charAt(3)) && method.getParameterTypes().length == 0 && (Collection.class.isAssignableFrom(method.getReturnType()) || Map.class.isAssignableFrom(method.getReturnType()) || AtomicBoolean.class == method.getReturnType() || AtomicInteger.class == method.getReturnType() || AtomicLong.class == method.getReturnType())) |
方法名长度大于等于4 && 非静态方法 && 以get开头且第4个字母为大写 && 无参数 && 返回值类型继承自Collection Map AtomicBoolean AtomicInteger AtomicLong

找到getter setter对应的字段后,会把字段名、字段对应的方法、类对象等打包成fieldInfo并add到FieldList中

最后用内省拿到的各种东西去构建JavaBeanInfo;返回实例化对象;

比较有意思的一个点是在构建javabeaninfo的时候会去对每一个fieldInfo进行判断,当然这个就是最开始在build的时候new的一个点;程序将拿到的属性和相应的方法放进去;这里会进行判断getOnly属性;意思是此属性是否只是有getter没有setter;这个点和一个叫asm的有关;asm是会对fastjson的性能有一定的优化,避免反射导致的开销;


因为存在getOnly类型的方法,所以会掉用JavaBeanDeserializer构造方法;然后会再次把上面说的去拿到setter和getter的操作进行一遍;再此期间fastjson会给每个bean定制反序列化器;

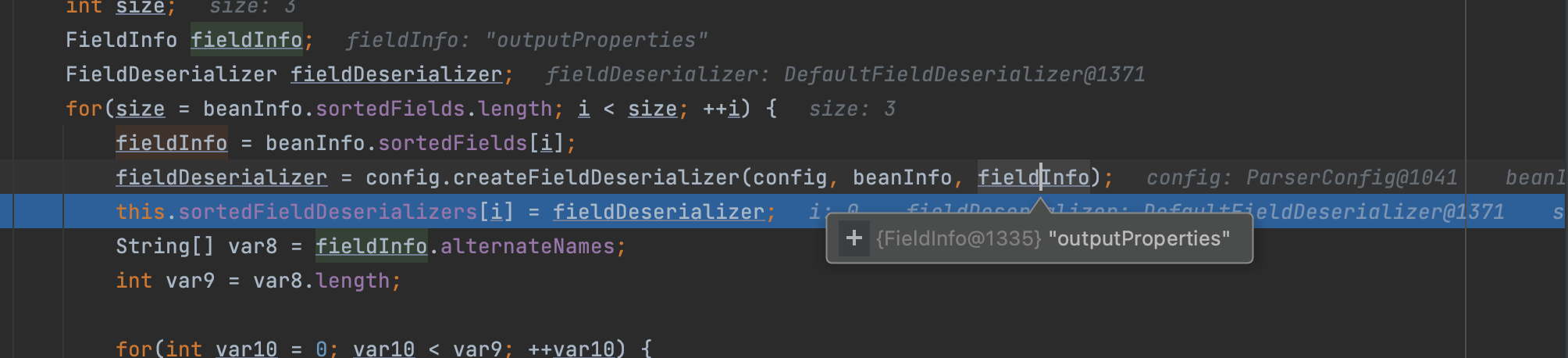
默认是DefaultFieldDeserializer;注意,这里的反序列化器针对的属性只是第二大步中由method中推演出来的几个属性,所以在第三大步对于目标对象属性反序列化的时候无法match到相应Field的deserializer;所以会自动生成拓展的反序列化器,当然这是后面分析的;

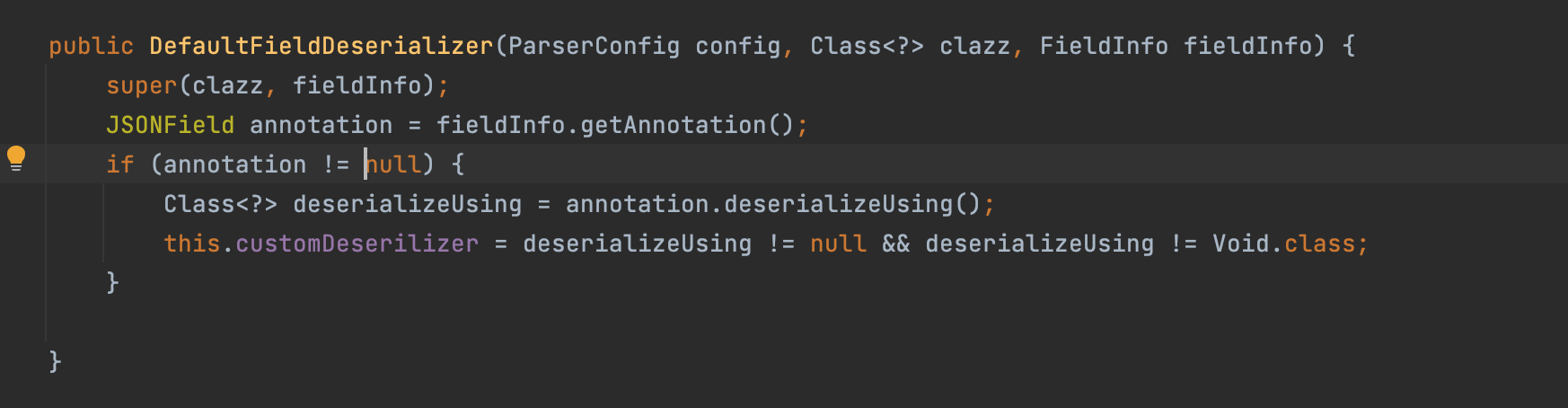

然后把每个属性的反序列化器生成之后放在sortedFieldDeserializers里;

在最后回到ParserConfig#getDeserializer方法,调用putDeserializer方法,将生成的反序列化器与@type传入的class类进行关联,放入目标类无参构造器,最后返回反序列化器;
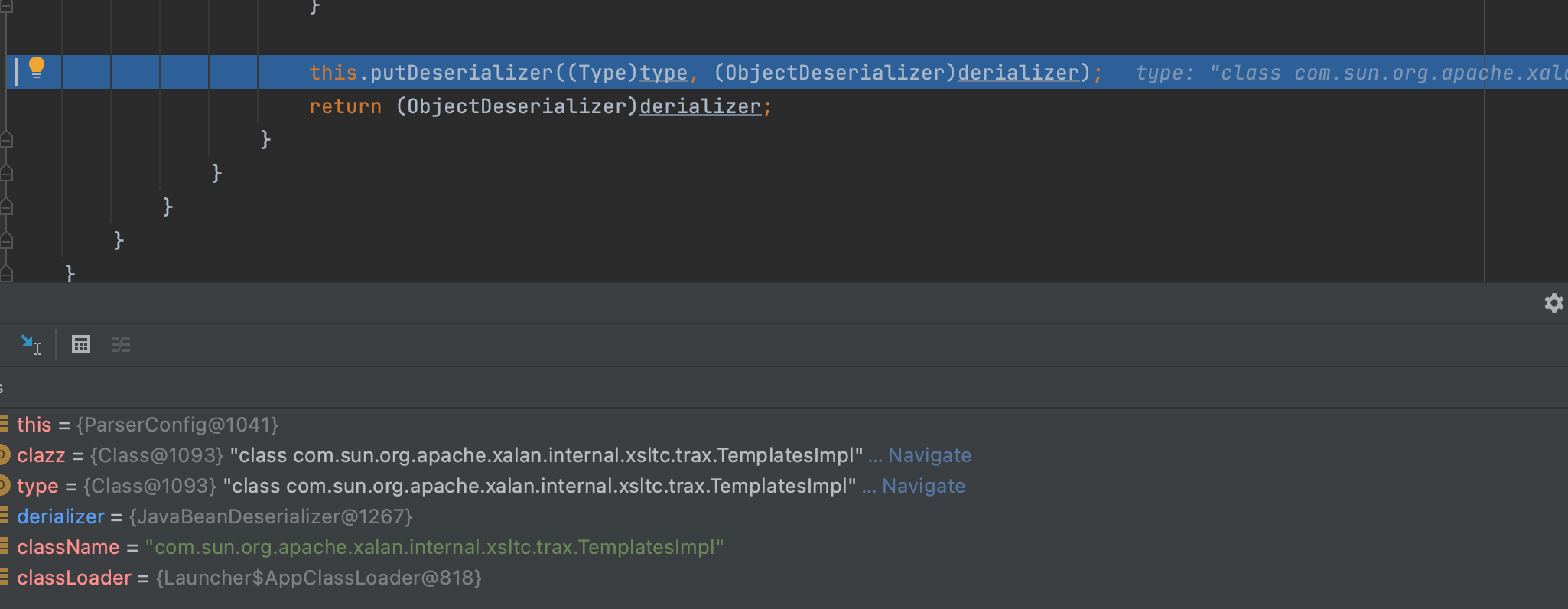
然后return;至此JavaBeanDeserializer定制完成,然后就是反序列化TemplatesImpl;
DefaultJSONParser.class 下;
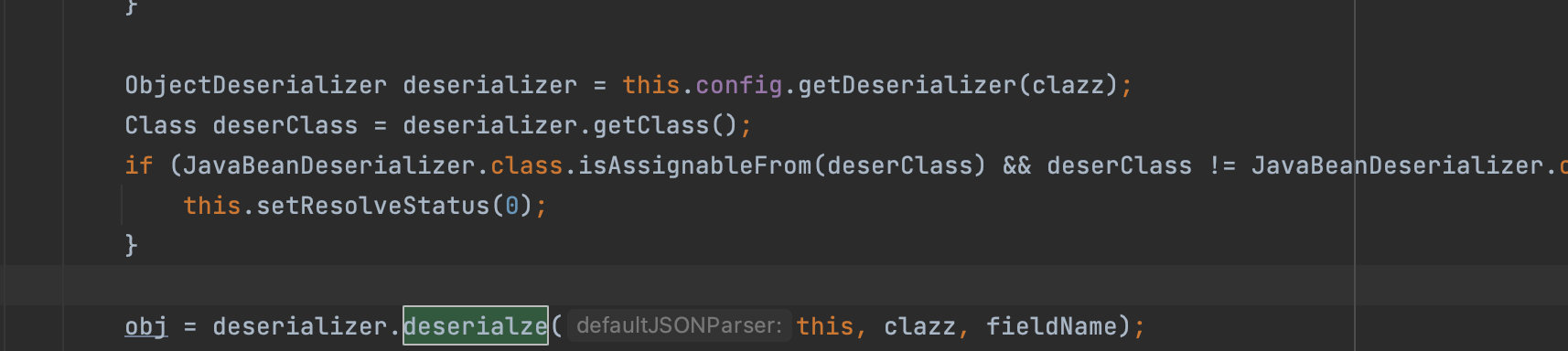
deserialze往下跟几步会进入label1289,从宏观来看主要的操作都在label1289和其子label中,做了以下这几件事情。
创建TemplatesImpl对象;

继续scan json之后将后续的值进行反序列化;因为scan json后拿到的key没有match到原本第二大步中method推演的属性;所以if走到最后,这里最后调用parseField对scan的json的key(类属性)进行反序列化;
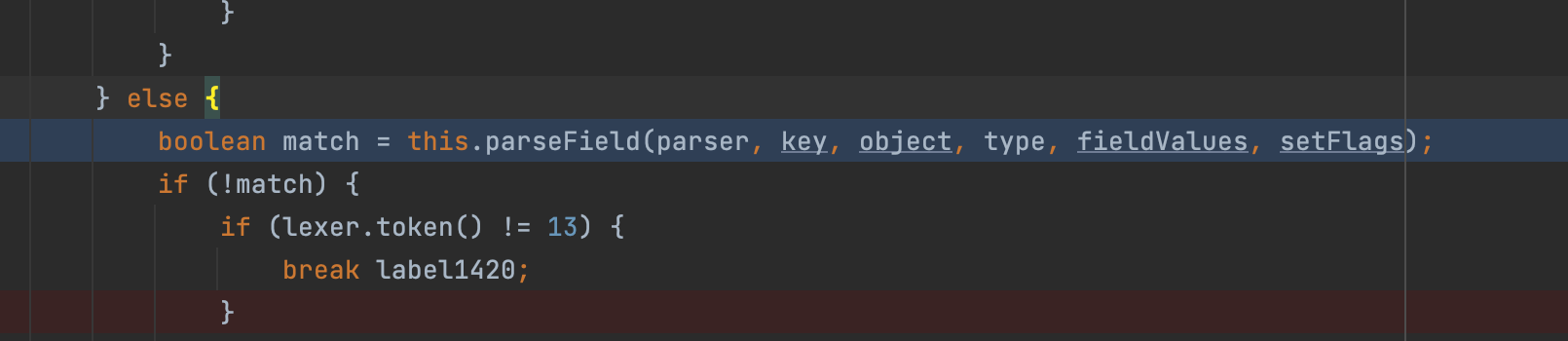
会先去寻找是否在之前构造有相应key属性的反序列化器;这里最后的结果为null;追溯一下不难发现;
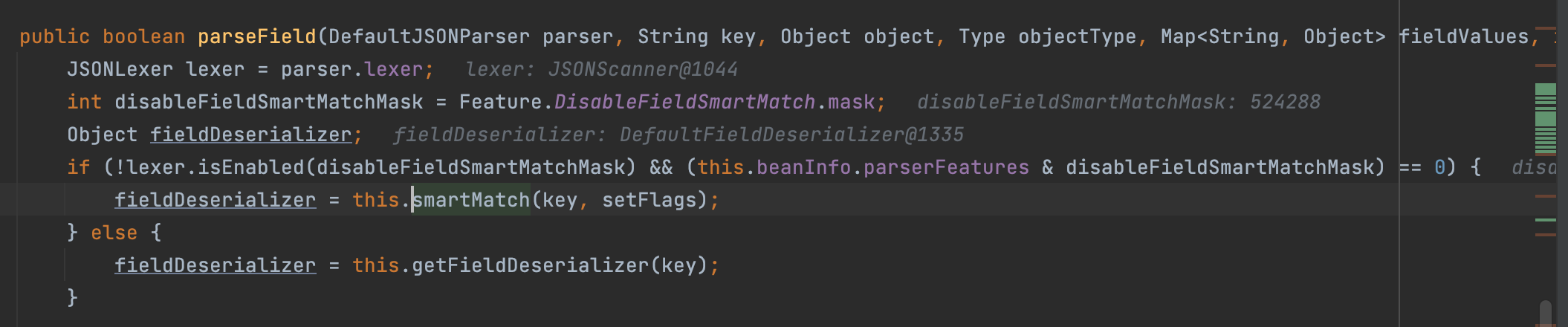
回到parseField方法中,设置Feature.SupportNonPublicField状态,并根据状态值进入if条件判断的代码块中,生成extraFieldDeserializers扩展的反序列化器。再从反序列化器中取出从fastjson获取的json数据中指定的属性。
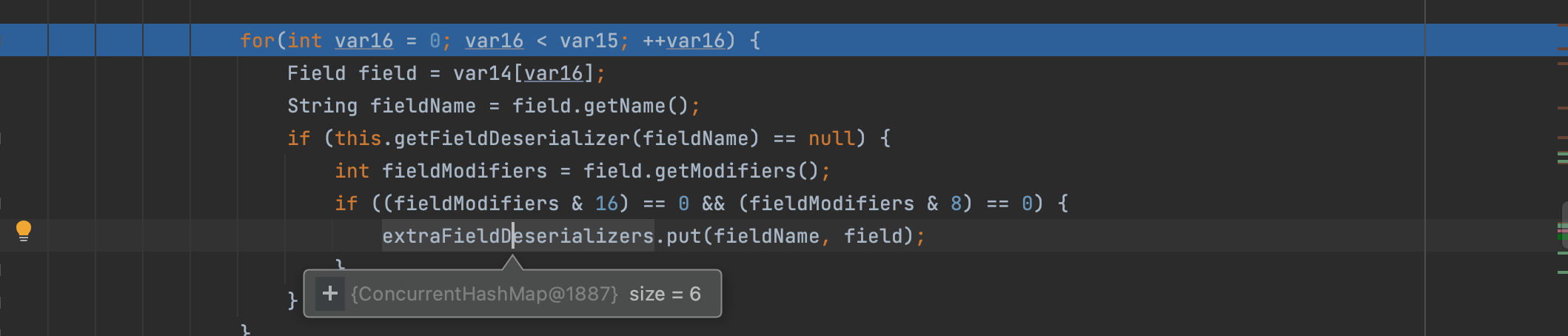
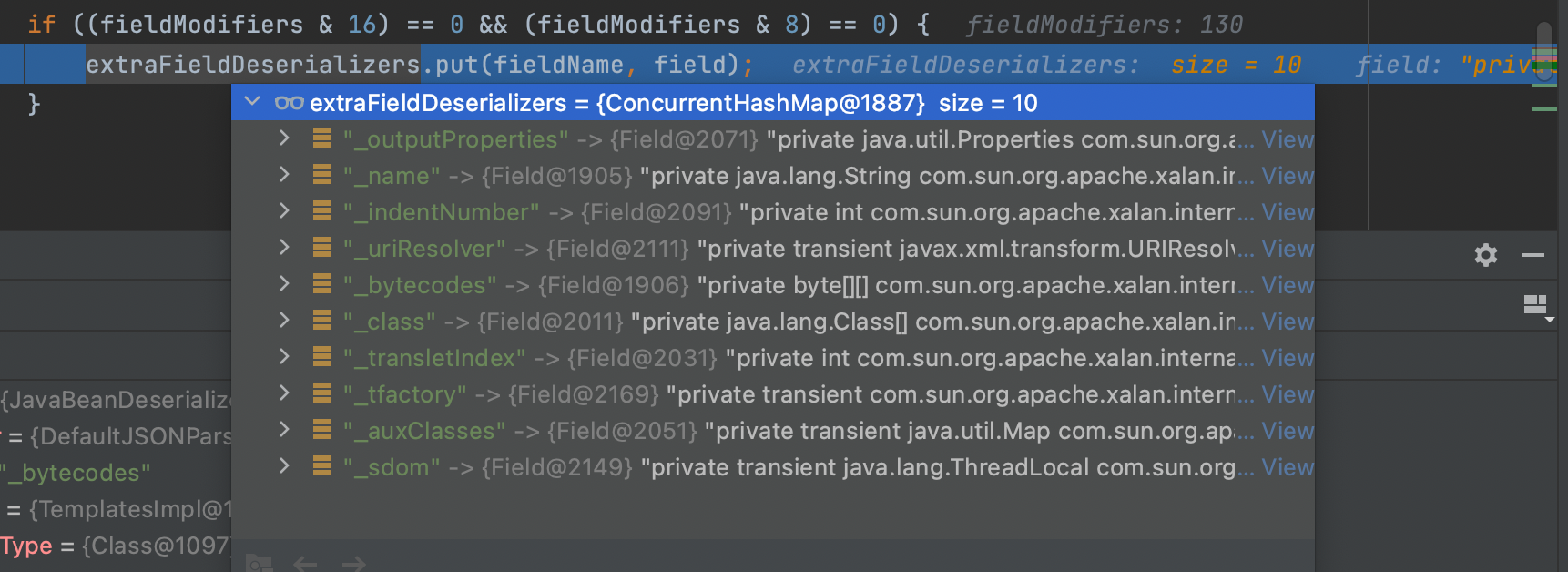
然后开始从拓展的反序列化器中get到json中的属性;通过反射进行处理;
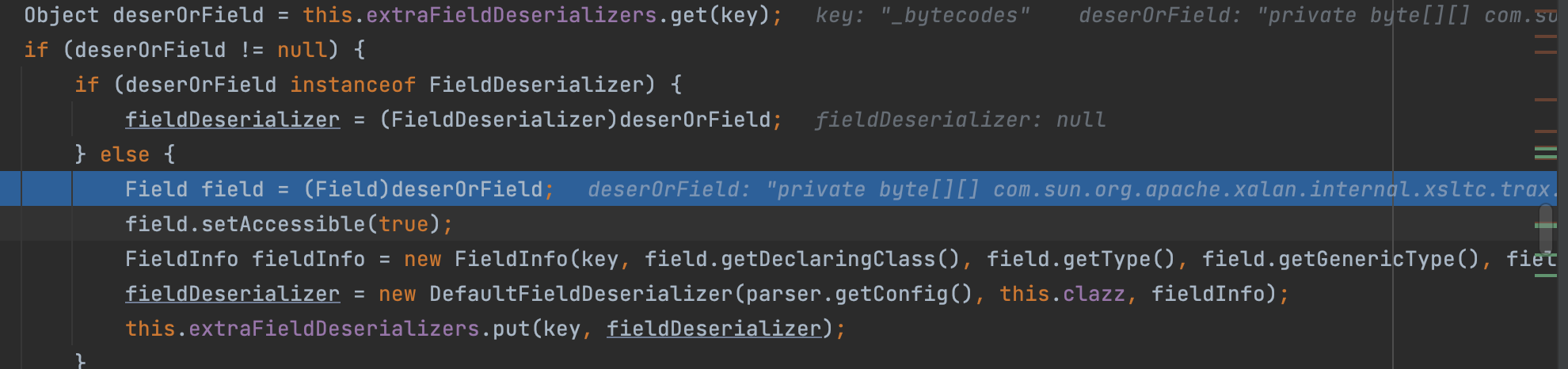
然后调用parseField方法,按照获取deserializer反序列化器的流程,获取fieldValueDeserilizer反序列化器。得到fieldValueDeserilizer反序列化器,在parseField方法中调用deserialze方法进行反序列化。


FieldValueDeserializer反序列化器是调用parseConfig类下的getDeserializer方法;先去config中注册好的反序列化器中查找;

这里因为是数组;所以在内部没有注册反序列化器的时候会经过一系列判断;如下图:

拿到ObjectArrayCodec反序列化器;

继续追踪一下调用栈:

DefaultJSONParser.parseArray();
因为token被检测出来是 [; 也就是14;所以nexttoken就会设置为15;具体可debug就知道;因为只是看属性,所以随意选择属性点无妨;
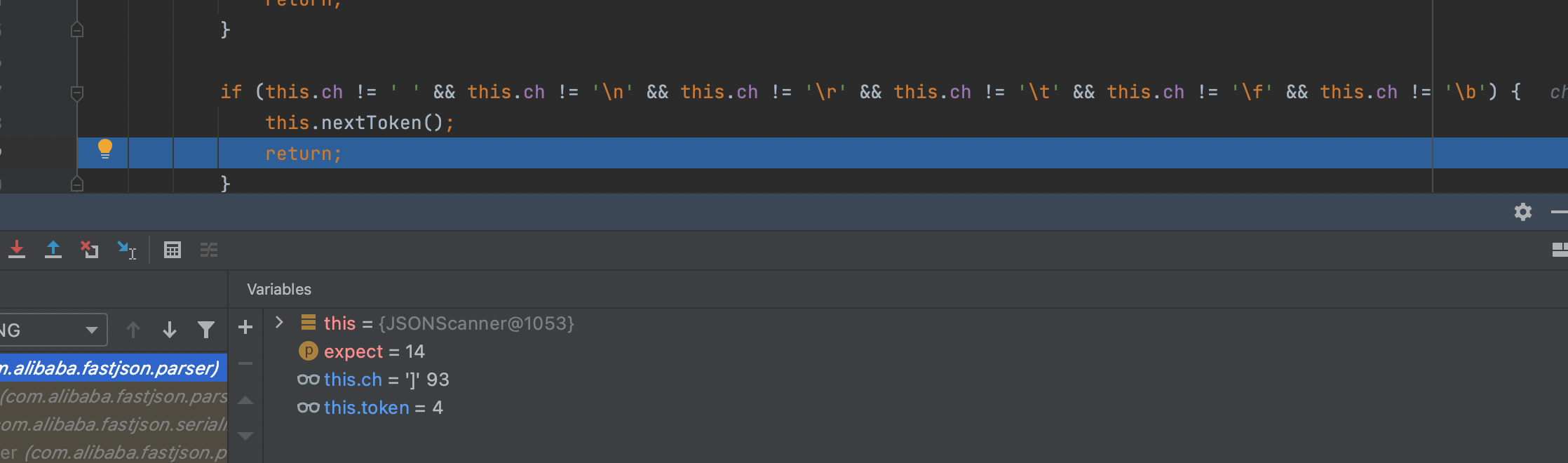

在DefaultJSONParser类下通过lexer.token()方法去调用JSONScanner类下的token方法获得token;判断[]之前数据类型,返回token为4,相应的为string;至此程序拿到的信息是:bytecode是一个数组类型,里面的数据是string类型;然后继续调用DefaultJSONParser下的743行对bytecode进行相应的反序列化;


调用数组解析器进行解析,因为里面数据为string类型,所以这里将string类型数据当作byte类型来读取;在此期间会进行base64解密,相应的流程可以看以下两个图的debug调试;两个都发生在数组解析器中;ObjectArrayCodec;


最后返回相应的数据

并且将其放在new的JSONArray数组里;
最后利用toObjectArray函数将其打包成对象数组;

最后调用setvalue进行赋值;将对象数组赋值给TemplatesImpl中对应的属性中;

其他的属性都雷同的方法进行反序列化,调用反射进行相应的赋值;但是有一点不同的是,当去反序列化_outputProperties的时候,因为这个属性是getOnly;所以在调用setValue方法反射
FieldDeserializer class下setValue方法;最开始会去利用属性去fieldInfo封装中get到method;但是显然没有相应的method;所以走到最后一步直接set值;

但是有趣的是如果get到相应的method就会去进行一系列的if判断,判断是否属于getOnly和其参数类型等等;
解析_outputProperties的时候,因为在TemplatesImpl对象中可以匹配到相应的方法,这在之前已经打包放在了FieldInfo中;所以此处可以很轻易的从FieldInfo中拿到相应方法,进入getOnly的判断,这里显然是符合getOnly类型的,最后判断其返回值是否是Map的子类,这里不难发现追溯一下;其返回值类的父类继承Map接口;所以符合,然后这里直接通过反射调用getOutputProperties方法;其实这里及时不是Map的子类,也会在后面也进行相应方法的调用;


到此分析过apache的commonscollections的师傅想来已经明白了。 最后通过getTransletInstance方法下的newInstance进行恶意类加载,这里恶意类追溯下不难发现是在defineTransletClasses方法中由bytecodes倒入的,这也是为什么构造bytecodes去进行给bytecodes赋值的原因;最后效果便是导致攻击者构造的恶意类下static模块的恶意代码执行达到rce;
最后值得一提的是json数据中同样存在_tfactory属性,但是追溯TemplatesImpl中即没有其getter也没有其setter;但是无伤大雅,我们设置_tfactory为{ },fastjson会调用其无参构造函数得_tfactory对象;这样就避免在defineTransletClasses方法中出现异常退出,如下图所示,让程序不异常退出是从bytecodes中拿到相应恶意类的关键;
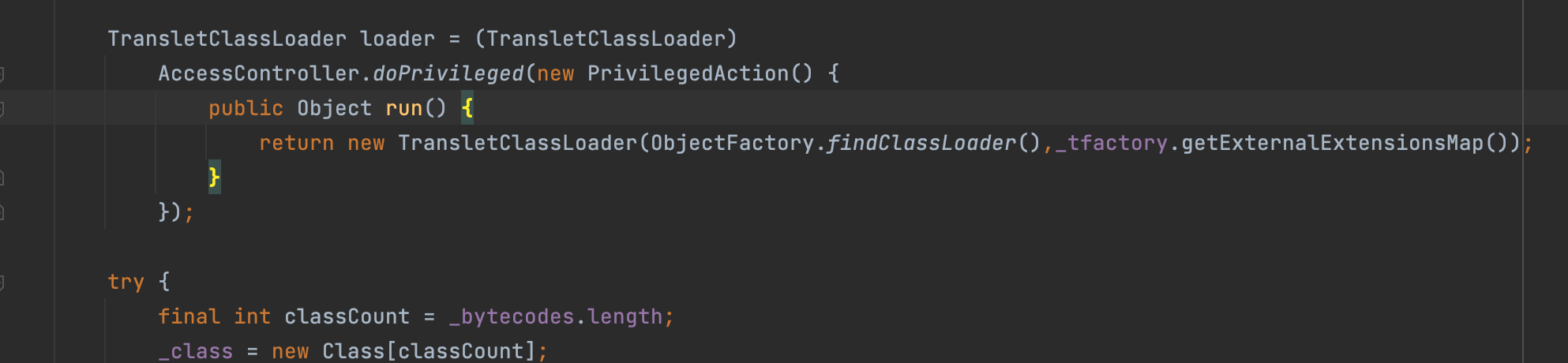
其实jndi的攻击原理和Templatesmpl的原理很相似;利用的都是fastjson会在自定义javabeanderserializer的时候会为每个Fileinfo定义deserializer;这里每个Fileinfo就是相应域被封装之后的对象;


默认情况下都是DefaultFieldDeserializer;当然其判断条件是是否有注解,可以看如下:

判断其是否有field注解或者方法的注解;如果有则采取另外的措施;所以一般情况都为DefualtFieldDeserializer;
最后利用put方法将拿到的FieldInfoDeserializer和需要反序列化的class关联(将其放到parserConfig配置文件中;):这里利用asm生成相应的反序列化器;直接利用javabean进行反序列化避免了反射的开销;也避免了非public域的赋值问题;(Templatesmpl中就需要考虑这个问题,之前已经分析过)
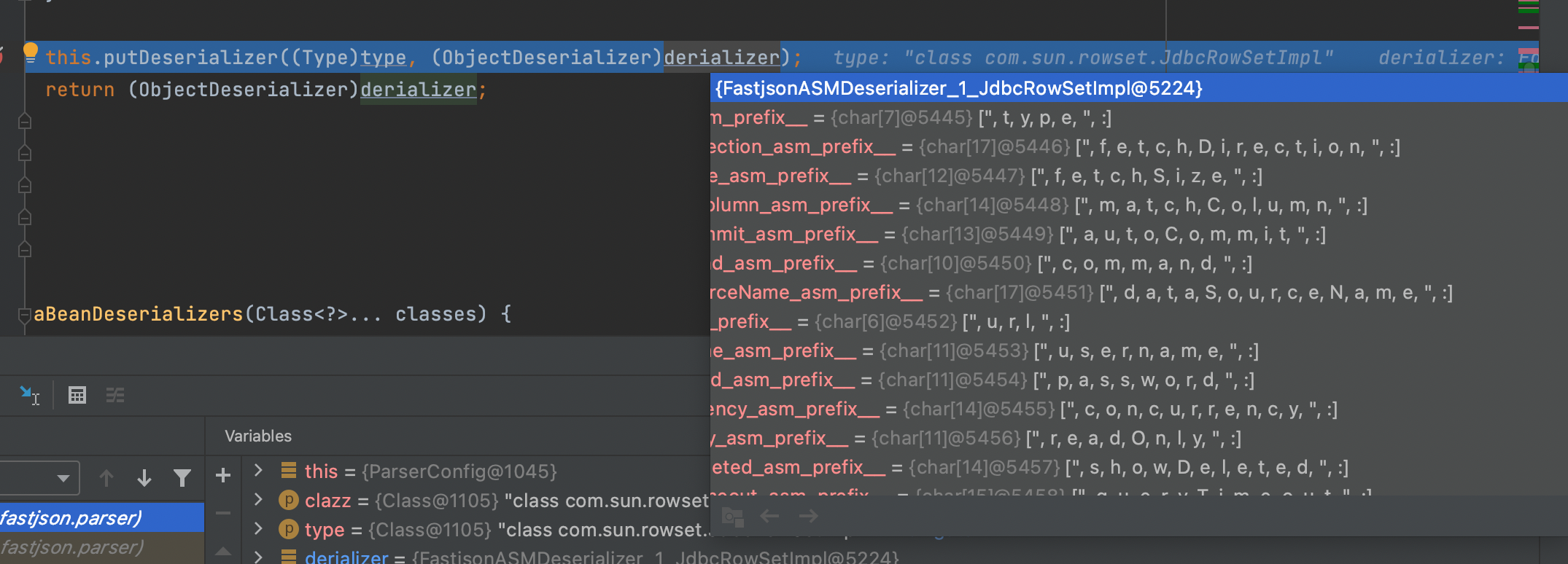
然后和之前分析的一样,绑定之后返回相应的反序列化器集合对象;
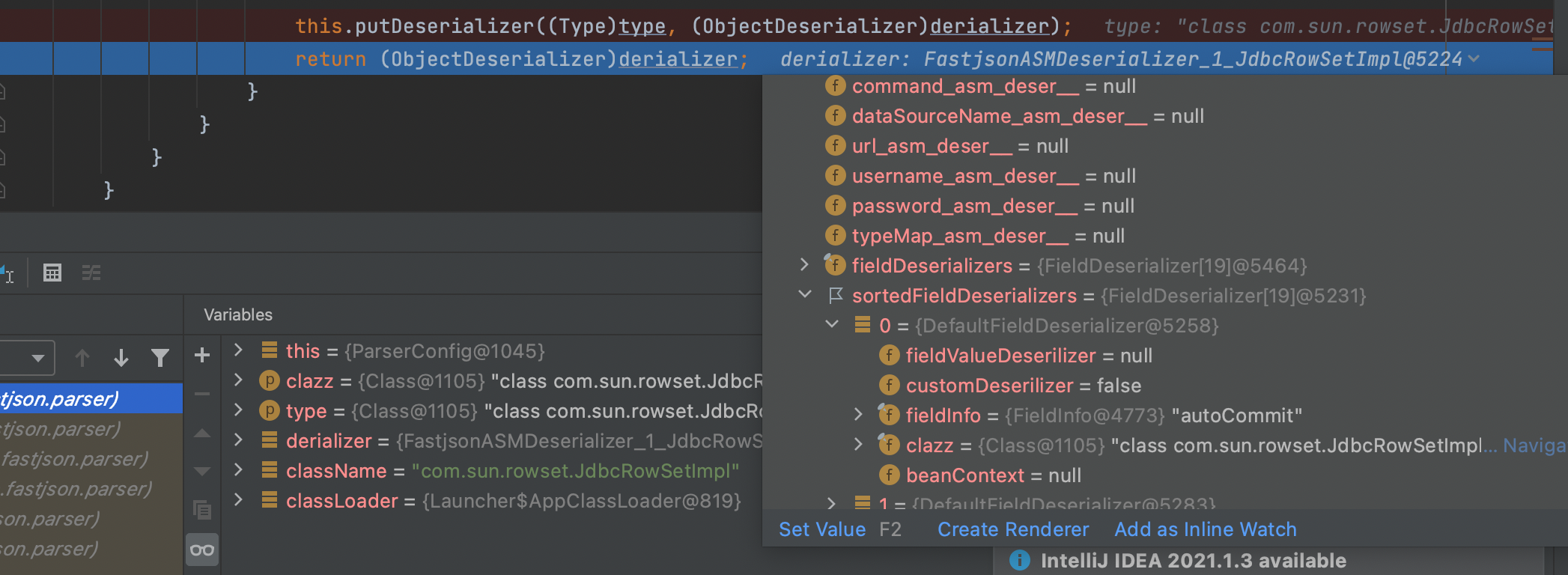
可以看到在之后从config中get到相应的deserializer;
两种链的一个小区别就是jndi链在生成javabeandeserializer的时候进行内省的时候拿到的getter和setter以及file域;是不存在getonly类型的,所以会直接使用asm字节技术直接生成javabeandeserializer反序列化而没必要考虑那些非共有的域赋值的问题;而templatesmpl因为其中_outputProperties域为getonly类型,所以fastjson还是调用了反射的原理去调用getOutputProperties;方法这也是Templateslmpl攻击链成功的原因;而且因为Templateslmpl是利用反射,所以还要考虑到相应的private域的赋值问题,所以需要设置supportNonpublicField,这样fastjson才会给每个域都配值相应的反序列化器;默认也就是DefualtFieldDeserializer实现原理就是去到相应的parserConfig下去直接对接FieldValueDeserializer;根据json传入数据的类型进行处理然后反射赋值;