
之前分析了java的urldns链,总的来说比较简单和基础,但是为了将代码问题理解的更加透彻,就需要细致分析下HashMap;我将致力java的安全研究;
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。在hashmap内部,数据的存储是按照数组和链表结合的复杂结构;数组被分成一个个bucket;通过哈希值来确定键值对在这个数组中的寻址;哈希值相同的键值对则以链表的形式来存储;具体如下图:
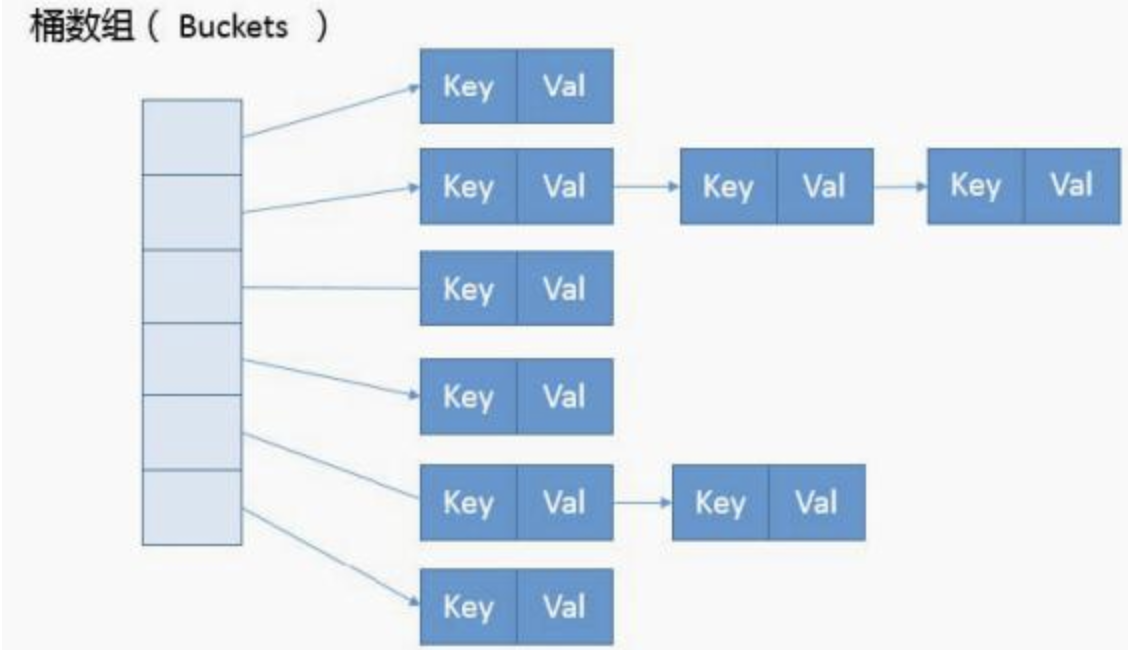
HashMap的key和value可以相同也可不同,HashMap 中的元素实际上是对象,一些常见的基本类型可以使用它的包装类。
HashMap<Integer,String> s1mple = new HashMap<Integer,String>();或者HashMap<String,String> s1mple = new HashMap<String,String>();
1 | import java.util.HashMap; |
一个简单的代码实例可以理解,利用put进行插入数据;追溯一下数据的来源;其实是每次插入一个数据都是进行了一次new一个node节点;然后按照hash来进行放置;
在第一个put处打下断点;然后调试一下;
1 | public V put(K key, V value) { |
发现其进入了putVal函数,这里后续也是我们urldns漏洞产生的一个点;在这个函数里调用了hash来去计算key的hash值;然后按照hash值来给接下来新的node节点进行位置的排放;这个点后续追溯时进行细说;
1 | static final int hash(Object key) { |
进入hash函数;传入对象类型的key;然后明显后续进行了hashCode方法;继续追溯;
1 | public int hashCode() { |
这里因为传入的为String对象的值,所以去到String类下去调用hashcode方法;这里取的String的ascii十进制的值;我们传入为”1”,所以这里为49;这直接hash=h;然后进行return;然后和逻辑右移16位的值进行亦或运算获得最后的hash值;然后回到put函数;进入putVal函数;追溯下;
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
这里先进行定义node链表数组,和一个node节点,整数n,i;table在类中有定义;
1 | transient Node<K,V>[] table; |
这里首先定义个空;然后if过;进入if内逻辑;进行追溯函数调试如下:
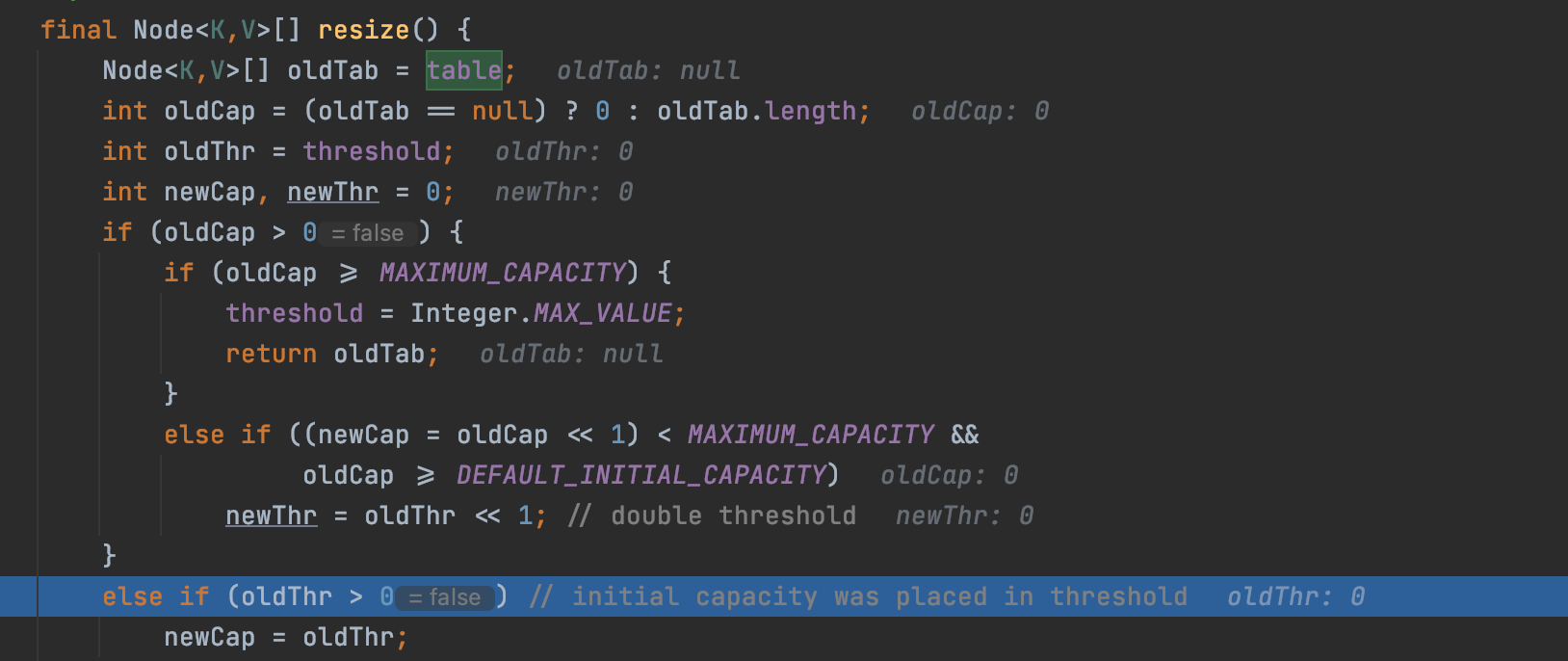
逻辑中将oldCap置为0;所以跳过if函数,直接进入下面的else if函数判断,也无法success;
进入else函数,这里写一下;
1 | else { // zero initial threshold signifies using defaults |
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
可以追溯发现newCap为默认的值;16;newThr为12;

然后new了一个节点类型的对象;大小为16个字节长度;然后给table赋值;将table设置为HashMap节点实例;接着下面的if语句为false;直接跳过进行最后的return;return newTab;也就是return了个node节点对象;返回最开始的函数;

因为之前说的长度为16个字节,所以这里length获取长度为16;进入if;这里hash取值之前的字节的ascii十进制;进行与运算,最后结果为1;最后获取该hash寻址链表的第一个元素;因为最开始为空的节点,所以这里的链表也自然为null;进入if的代码逻辑;因为之前为一个空的节点,链表也为空;所以这里就直接new了一个新的节点;
相当于我们之前审的源码逻辑进行的先是hash寻址的计算,然后判断该地址的相应位链表是否为空,如果为空,直接new一个新的节点放入链表;调试节点结果如下;返回一个新的node节点;包括hash寻址,key,value,next;


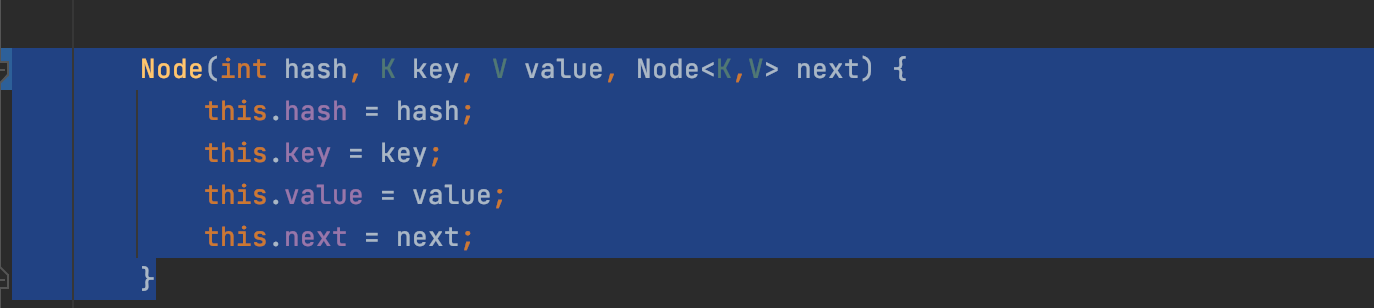
完成这一系列的逻辑操作之后,重回到putVal方法;最后完成节点的插入;

到此整个put的逻辑走完,新的node节点也已经插入;该键值对的地址就为之前的字节ascii码和ascii码进行逻辑右移16位去进行亦或运算得到;
然后我们之前已经插入了一个node节点,现在观察插入第二个节点的流程;继续断点走起;
1 | public V put(K key, V value) { |
同样是进入putVal的逻辑;

同样进行hash去计算地址;然后putVal去进行实力化node节点;这里自然h为50;(因为是2);
唯一不一样的地方为:
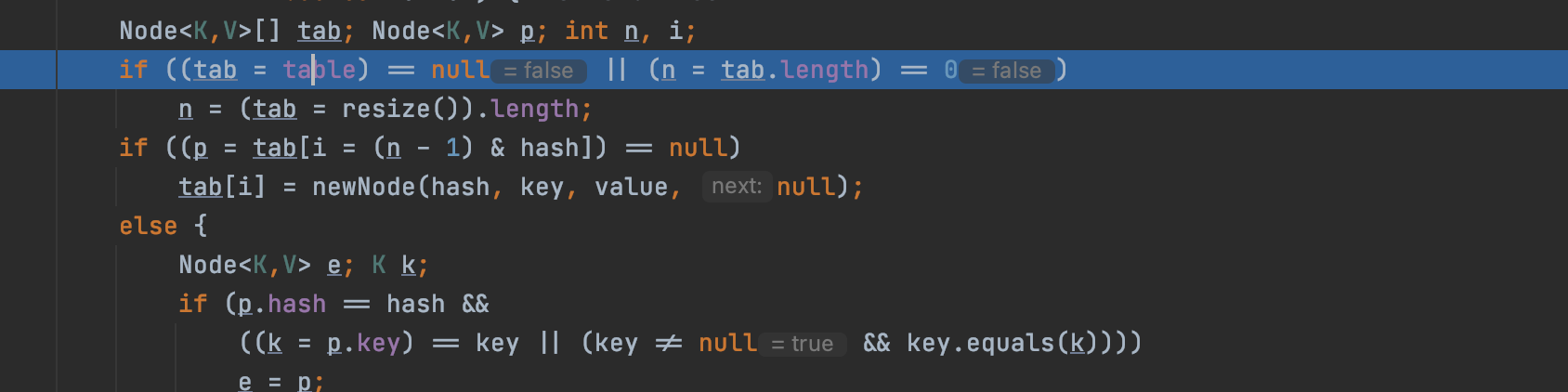
基于之前已经插入了一个node;已经给table进行了赋值,所以这里已经不为null;所以直接跳过if代码的逻辑;不用在去进行resize获取大小,直接利用之前的进行下一句if的判断;这里(n - 1) & hash为2,因为之前的hash地址是字节的ascii码和其ascii十进制逻辑右移16为进行亦或得到;逻辑右移16位后为0,所以其hash地址就为其ascii的十进制值;最后相应的地址和key,value还有next配置完后,直接new插入一个新的node节点;

很显然的是第二个键值对是被放入了tab的第二个位;也就是数组的第二个位置;然后hash地址为50;如果有键名或者其他因素导致hash寻址相同,那么就会被放入相同的数组位值的链表中;那就是后续的代码了;感兴趣的师傅可以追溯,不过基本原理就是如此;
由此也可得到一个结论,在序列化 HashMap 类的对象时, 为了减小序列化后的大小, 并没有将整个哈希表保存进去, 而是仅仅保存了所有内部存储的 key 和 value. 所以在反序列化时, 需要重新计算所有 key 的 hash, 然后与 value 一起放入哈希表中. 这也就是导致了后期的urldns漏洞的产生;已经写过文章;